BLOG POST
Real-Time Messaging with ZeroMQ: Patterns That Actually Work

People keep asking me why I chose ZeroMQ instead of a "proper" message queue. The answer is straightforward: I needed to push events from backend services through a processing pipeline into Elasticsearch for indexing and simultaneously fan them out via Socket.IO to connected browser clients - all in real time, all under ten milliseconds end-to-end. A broker sitting in the middle of that path, adding milliseconds per hop and consuming memory just to exist, was not an option. The budget was three t2.medium EC2 instances. There was no room for an Erlang runtime eating 800 MB of RAM to babysit queues I didn't need.
What follows is everything I've learned - the patterns that work, the patterns that don't, the production gotchas that cost me weekends, and enough code and architectural detail that you could rebuild the whole thing from this post. This is the guide I wish existed when I started.
Grab coffee. This is going to be long.
The system we're building
Before diving into ZeroMQ specifics, let me show you what we're actually building. This is a real-time notification and event processing system for a platform with a few thousand concurrent users. The requirements:
- Backend services (Node.js) generate events - user actions, system alerts, status changes, transactional notifications
- Events need to be routed through a processing pipeline - enrichment, deduplication, transformation, filtering
- Processed events get indexed into Elasticsearch for search, aggregation, and historical queries
- Simultaneously, relevant events get pushed to connected browser clients via Socket.IO in real time - sub-second from event generation to browser notification
- The system must handle bursty traffic - quiet periods punctuated by spikes when something happens across the platform
- The whole thing runs on three AWS t2.medium instances because that's the budget
Here's the high-level view:
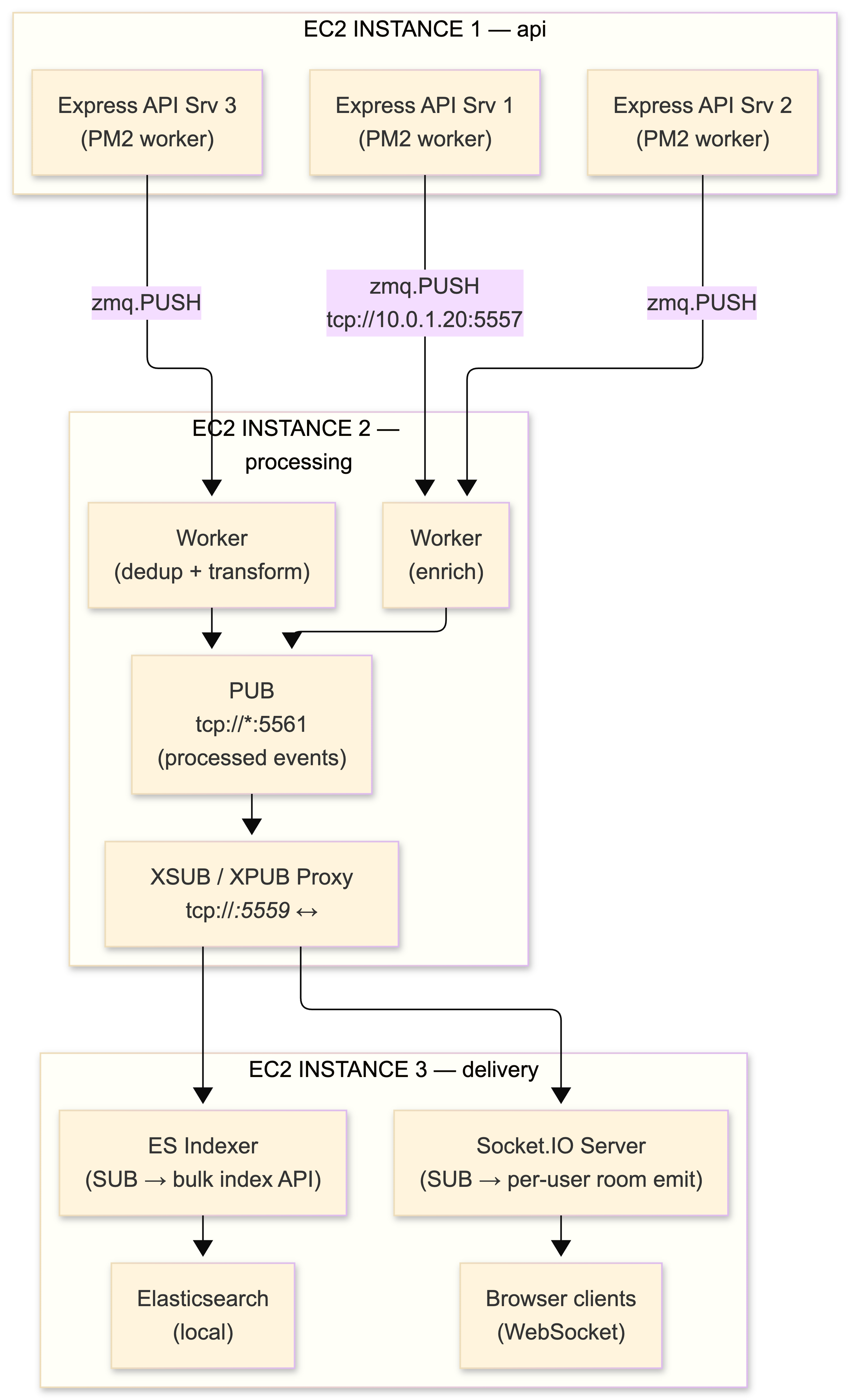
Events flow top to bottom: API servers generate them, the processing tier transforms them, the delivery tier pushes them to Elasticsearch and Socket.IO simultaneously. ZeroMQ is the nervous system connecting all of it. No broker in sight.
Why ZeroMQ and not a broker
I evaluated RabbitMQ, Redis Pub/Sub, and a couple of others before choosing ZeroMQ. Here's the honest assessment:
RabbitMQ is excellent software. I have nothing against it. But it needs the Erlang runtime, it needs at least 512 MB–1 GB of memory just for the broker process, and adding it means another piece of infrastructure to deploy, monitor, and maintain on EC2. On a t2.medium (4 GB RAM), the broker alone eats a quarter of my memory budget before my application even starts. When you're running Node.js processes alongside Elasticsearch on the same instance (yes, I know, I'll explain), every megabyte counts.
Redis Pub/Sub was tempting because we already had a Redis instance for caching. But Redis Pub/Sub has no persistence, no acknowledgment, no message buffering - if a subscriber is offline when a message arrives, it's gone. That's also true of ZeroMQ's PUB/SUB, but ZeroMQ gives me PUSH/PULL for the pipeline stages where I need reliable delivery to at least one worker, and its performance overhead is essentially zero. In a C++ benchmark comparison, ZeroMQ PUB/SUB delivered roughly 410,000 msgs/sec versus Redis Pub/Sub at 59,000 - a 7× advantage. At the scale I'm working at the difference doesn't matter much, but the architectural flexibility does.
Kafka would be the right choice if I needed a distributed commit log with replay capability. I don't. My events are ephemeral notifications, not a permanent event stream. Kafka also wants ZooKeeper, which wants its own JVM, which wants its own memory, which wants its own EC2 instance. The budget for this project is three instances, not six.
So: ZeroMQ. No broker process. No runtime dependency. No daemon to manage. I npm install zmq in my Node.js services, create sockets, connect them, and start sending messages. The library handles reconnection, buffering, routing, and I/O threading internally. Total additional memory overhead: roughly 3–5 MB per process.
ZeroMQ is not a message queue
Despite having "MQ" in its name, ZeroMQ is not a message queue. It's a messaging library - a C library (libzmq) that you link against, which gives your application superpowers for moving discrete messages between processes and machines. There's no server to install. No daemon to configure. No broker process sitting between your services.
The "zero" originally meant "zero broker" and "zero latency." Pieter Hintjens, ZeroMQ's creator and the author of the indispensable ZeroMQ Guide (read it, all of it, cover to cover - it's the best technical writing I've encountered in years), expanded the meaning to include zero administration, zero cost, and zero waste.
His philosophy, and I'm paraphrasing from the zguide here: traditional message brokers are greedy central intermediaries that become too complex, too stateful, and eventually a problem. ZeroMQ inverts this - smart endpoints, dumb network. The intelligence lives at the edges, not in a central server. You choose the topology. Nothing is imposed on you.
The current stable release is libzmq 4.1.x (I'm running 4.1.4 on all instances). Version 4.0 introduced CURVE security - end-to-end encryption built on Daniel Bernstein's Curve25519 elliptic curve cryptography, baked right into the wire protocol (ZMTP 3.0). No TLS wrapper, no stunnel, no nginx reverse proxy. This matters when you're sending events between EC2 instances across a VPC - even within AWS, encrypt your inter-service traffic.
The mental model shift: these aren't TCP sockets
This took me the longest to internalize and it will save you weeks of confusion: ZeroMQ sockets are fundamentally different from TCP sockets.
TCP sockets give you byte streams. You push bytes in one end, pull bytes out the other, and you're responsible for framing, delimiting, parsing partial reads, managing reconnection, and handling every edge case yourself. Every Node.js developer has written the data += chunk; if (data.indexOf('\n') !== -1) { ... } dance at least once.
ZeroMQ sockets give you discrete, framed messages. You send a message object, the other side receives that exact message - complete, framed, no partial reads, no delimiter parsing. A single ZeroMQ socket can be connected to multiple peers simultaneously. Reconnection is automatic. Routing (round-robin, fair-queuing, pub/sub filtering) is built into the socket type. The ZMTP wire protocol handles framing at the transport layer.
In Node.js terms: where you'd normally build a TCP server with net.createServer(), handle the 'data' events, buffer partial messages, parse your framing protocol, manage a connection table, implement reconnection with backoff - ZeroMQ does all of that internally. Your code deals with complete messages and nothing else.
The other critical mental shift: bind vs. connect is about stability, not client/server roles. In traditional networking, the server binds and the client connects. In ZeroMQ, the stable node binds and the dynamic nodes connect. A worker that spins up and down connects to the long-lived service that binds. This means subscribers can bind and publishers can connect - the reverse of what you'd expect - and it works perfectly. On EC2, my processing proxy binds on fixed ports; the API servers and delivery services connect to it. When I scale up API server instances behind an ELB, the new instances just connect.
The six socket patterns and when to use each one
ZeroMQ's power comes from a small set of socket types implementing distinct messaging patterns. Each enforces specific send/receive behavior. Choosing the right pattern is the most important architectural decision you'll make.
Here's the cheat sheet I keep taped to my monitor (literally, printed out, stuck to the bezel with masking tape):
| Pattern | Socket Types | Direction | At HWM |
|---|---|---|---|
| REQ/REP | REQ ↔ REP | Synchronous RPC | Block |
| PUB/SUB | PUB → SUB | One-to-many broadcast | Drop (PUB) |
| PUSH/PULL | PUSH → PULL | One-to-one distribution | Block (PUSH) |
| DEALER/ROUTER | DEALER ↔ ROUTER | Async request-reply | Mixed* |
| PAIR | PAIR ↔ PAIR | Exclusive bidirectional | Block |
| XPUB/XSUB | XPUB → XSUB | Proxy-aware pub/sub | Drop (XPUB) |
* DEALER blocks at HWM; ROUTER drops. Know this distinction. It will matter at 3 AM.
REQ/REP - synchronous RPC and its fatal flaw
The simplest pattern. REQ sends a message, blocks until it gets a reply. REP waits for a request, processes it, sends back a response. The lock-step send→recv→send→recv cycle is enforced by the internal state machine - try to send twice without receiving and you get an EFSM error.
Under the hood, REQ prepends an empty delimiter frame (the "envelope") that enables routing through intermediaries. REP strips this on receive, saves it, and re-wraps the reply. When multiple REP servers connect, REQ round-robins across them; REP fair-queues from all clients.
In Node.js with the zmq binding:
server.js
// server.js - REP
var zmq = require('zmq');
var responder = zmq.socket('rep');
responder.bind('tcp://*:5555', function(err) {
if (err) throw err;
console.log('REP server listening on 5555');
});
responder.on('message', function(msg) {
console.log('Received: ' + msg.toString());
setTimeout(function() {
responder.send('World');
}, 100); // Simulate async work
});client.js
// client.js - REQ
var zmq = require('zmq');
var requester = zmq.socket('req');
requester.connect('tcp://localhost:5555');
var count = 0;
requester.on('message', function(msg) {
console.log('Got reply ' + count + ': ' + msg.toString());
count++;
if (count < 10) {
requester.send('Hello');
} else {
requester.close();
}
});
requester.send('Hello');Clean. Simple. And fatally flawed for production use: if the server dies mid-request, the REQ client hangs forever. There's no built-in timeout. The internal state machine is stuck waiting for a reply that will never come, and there is no way to reset it without destroying the socket entirely. In Node.js this is especially nasty because the hung socket silently blocks that communication channel - no error event, no timeout callback, nothing.
I don't use raw REQ/REP in production. Ever. You need the Lazy Pirate pattern (covered below) or DEALER/ROUTER. More on that later.
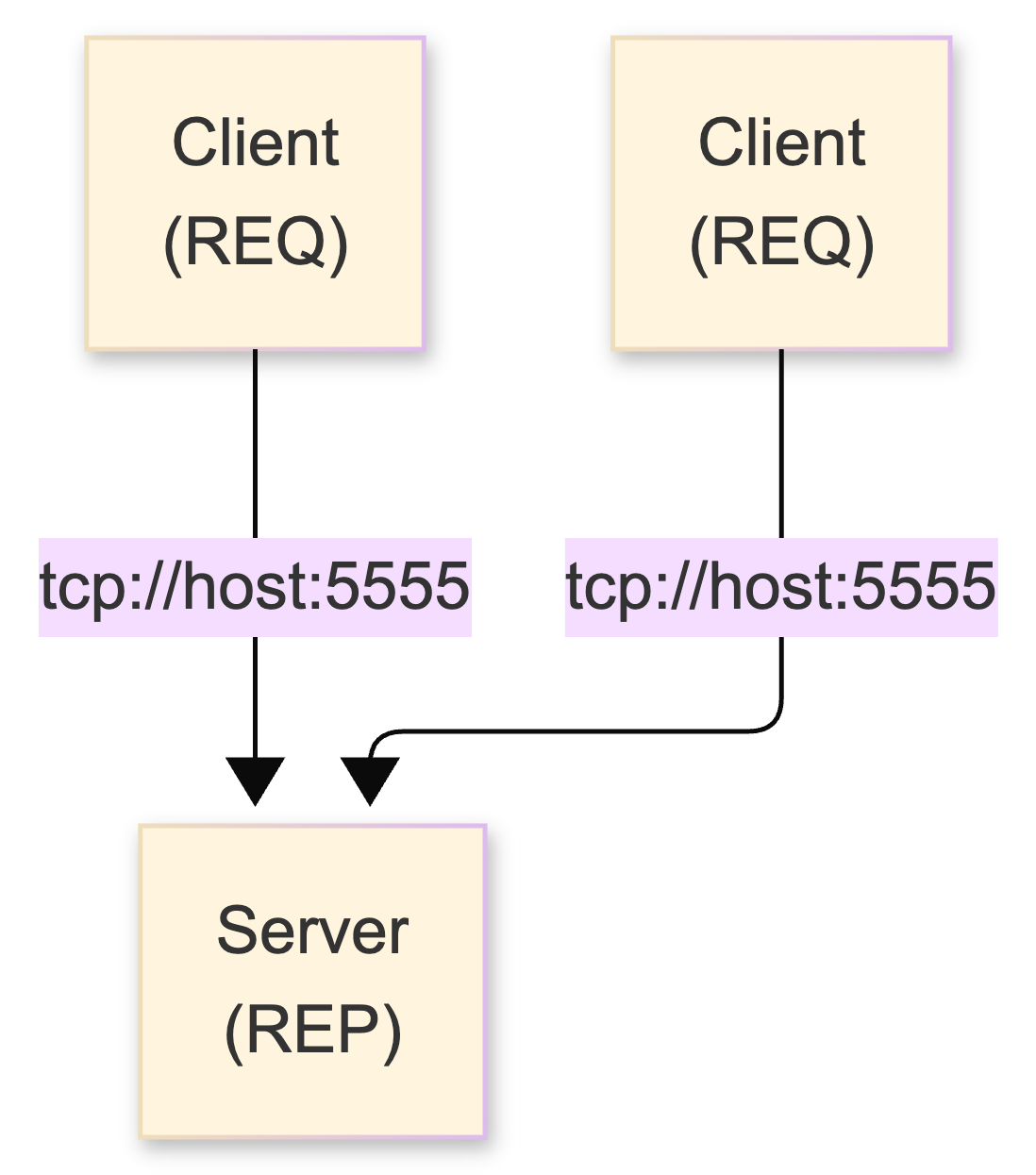
Flow: REQ sends → REP receives → REP sends → REQ receives. Strictly enforced. Violate the sequence = EFSM error. Server dies mid-request = client hangs forever.
PUB/SUB - broadcast with topic filtering
This is what I use for the fan-out stage - pushing processed events to multiple consumers simultaneously. A PUB socket sends messages to all connected SUB sockets, filtered by topic. Topics are byte-string prefixes: subscribing to "user.123" matches any message starting with those bytes. An empty subscription ("") receives everything.
Important detail that tripped me up: since ZeroMQ 3.x, topic filtering happens at the publisher side, not the subscriber. The PUB maintains per-subscriber queues and only sends matching messages. This was a huge performance win over 2.x where all messages hit the wire and were filtered locally. If you're reading older blog posts or Stack Overflow answers about ZeroMQ filtering, check the version - 2.x behavior and 3.x+ behavior are opposite.
publisher.js
// publisher.js - event broadcaster
var zmq = require('zmq');
var pub = zmq.socket('pub');
pub.bind('tcp://*:5561', function(err) {
if (err) throw err;
console.log('PUB broadcasting on 5561');
});
// Events come from the processing pipeline
function publishEvent(event) {
// Topic is the first frame - subscribers match on prefix
var topic = event.type + '.' + event.userId;
var payload = JSON.stringify(event);
pub.send(topic + ' ' + payload);
}
// Example: publishEvent({ type: 'notification', userId: '42', body: '...' })subscriber.js
// subscriber.js - event consumer (e.g., the ES indexer)
var zmq = require('zmq');
var sub = zmq.socket('sub');
sub.connect('tcp://10.0.1.20:5561');
sub.subscribe(''); // Subscribe to ALL events for indexing
sub.on('message', function(data) {
var spaceIdx = data.indexOf(' ');
var topic = data.slice(0, spaceIdx).toString();
var payload = JSON.parse(data.slice(spaceIdx + 1));
// Bulk-index into Elasticsearch
indexBuffer.push(payload);
if (indexBuffer.length >= 100) {
flushToElasticsearch();
}
});PUB sockets never block. When a subscriber's queue hits the high-water mark (default: 1000 messages), excess messages are silently dropped. When no subscribers are connected, all messages are discarded. This is by design - one slow subscriber cannot block every other subscriber. But it means PUB/SUB will lose messages and you design for it.
In our system, the ES indexer subscribes to "" (everything) for full indexing. The Socket.IO bridge subscribes to specific user topic prefixes for targeted delivery. If the ES indexer falls behind, it drops events and catches up - we handle this with a periodic full-reindex job. The Socket.IO bridge, being real-time only, accepts that dropped messages mean missed notifications (the client polls on reconnect).
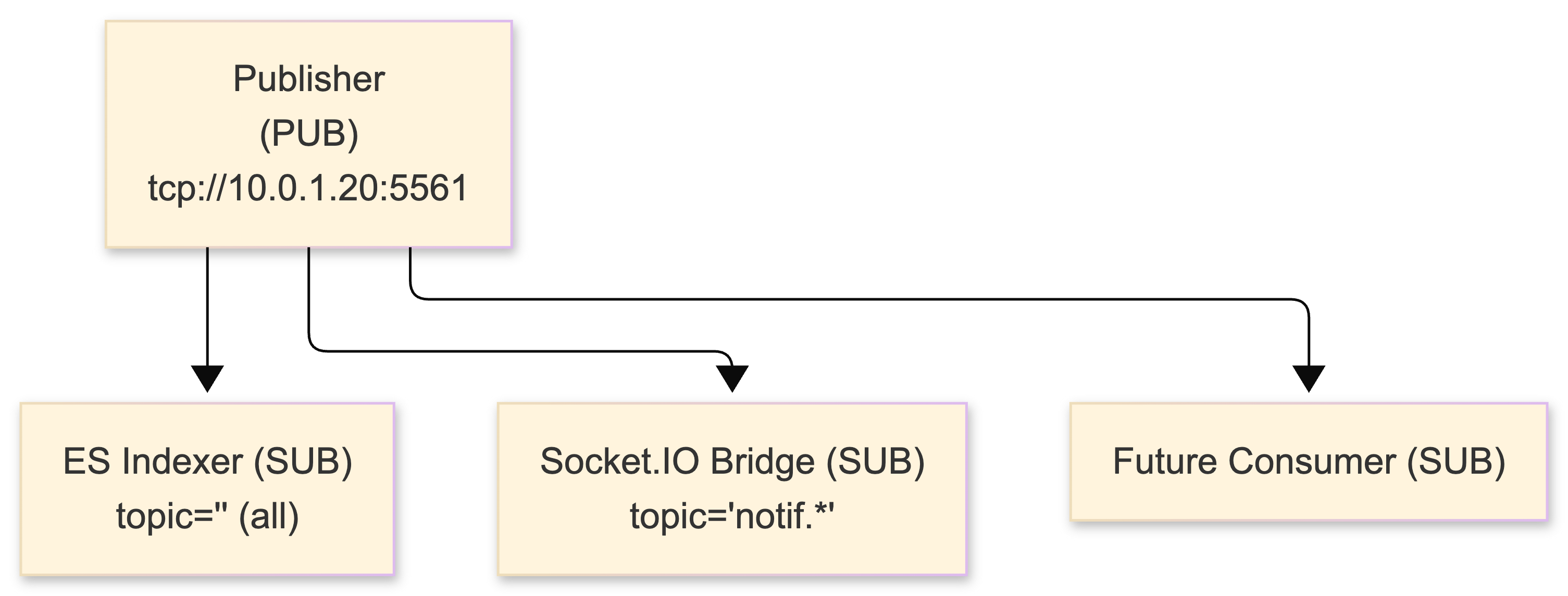
Filtering happens at PUB side (ZMQ 3.x+). Messages dropped silently at HWM. No error. No callback.
PUSH/PULL - parallel work distribution
Where PUB sends to all consumers, PUSH sends to one consumer at a time via round-robin. This is the backbone of our processing pipeline - the ventilator/worker/sink pattern.
API servers PUSH events into the pipeline. Multiple workers PULL them (each event goes to exactly one worker for processing), then PUSH results toward the delivery tier. Add more workers, get proportionally more throughput. Near-linear scaling until you hit the PUSH sender's rate or the network.
api-server.js
// api-server.js - event producer (runs on EC2 instance 1)
var zmq = require('zmq');
var pusher = zmq.socket('push');
// Connect to the processing tier's PULL endpoint
pusher.connect('tcp://10.0.1.20:5557');
// Called from Express route handlers when events occur
function emitEvent(event) {
event.timestamp = Date.now();
event.source = process.env.INSTANCE_ID || 'api-1';
pusher.send(JSON.stringify(event));
}
// Express routes use it naturally
app.post('/api/orders', function(req, res) {
// ... process order ...
emitEvent({
type: 'order.created',
userId: req.user.id,
orderId: order.id,
data: { amount: order.total }
});
res.json({ ok: true });
});worker.js
// worker.js - event processor (runs on EC2 instance 2)
var zmq = require('zmq');
var receiver = zmq.socket('pull');
receiver.bind('tcp://*:5557'); // Workers bind, producers connect
var sender = zmq.socket('push');
sender.bind('tcp://*:5558'); // Downstream consumers connect
receiver.on('message', function(data) {
var event = JSON.parse(data);
// Enrichment: add user metadata from cache
event.user = userCache.get(event.userId) || { id: event.userId };
// Deduplication: skip if we've seen this event ID recently
if (dedupeSet.has(event.id)) return;
dedupeSet.add(event.id);
// Transformation: normalize, add derived fields
event.processed = true;
event.processedAt = Date.now();
event.latencyMs = event.processedAt - event.timestamp;
sender.send(JSON.stringify(event));
});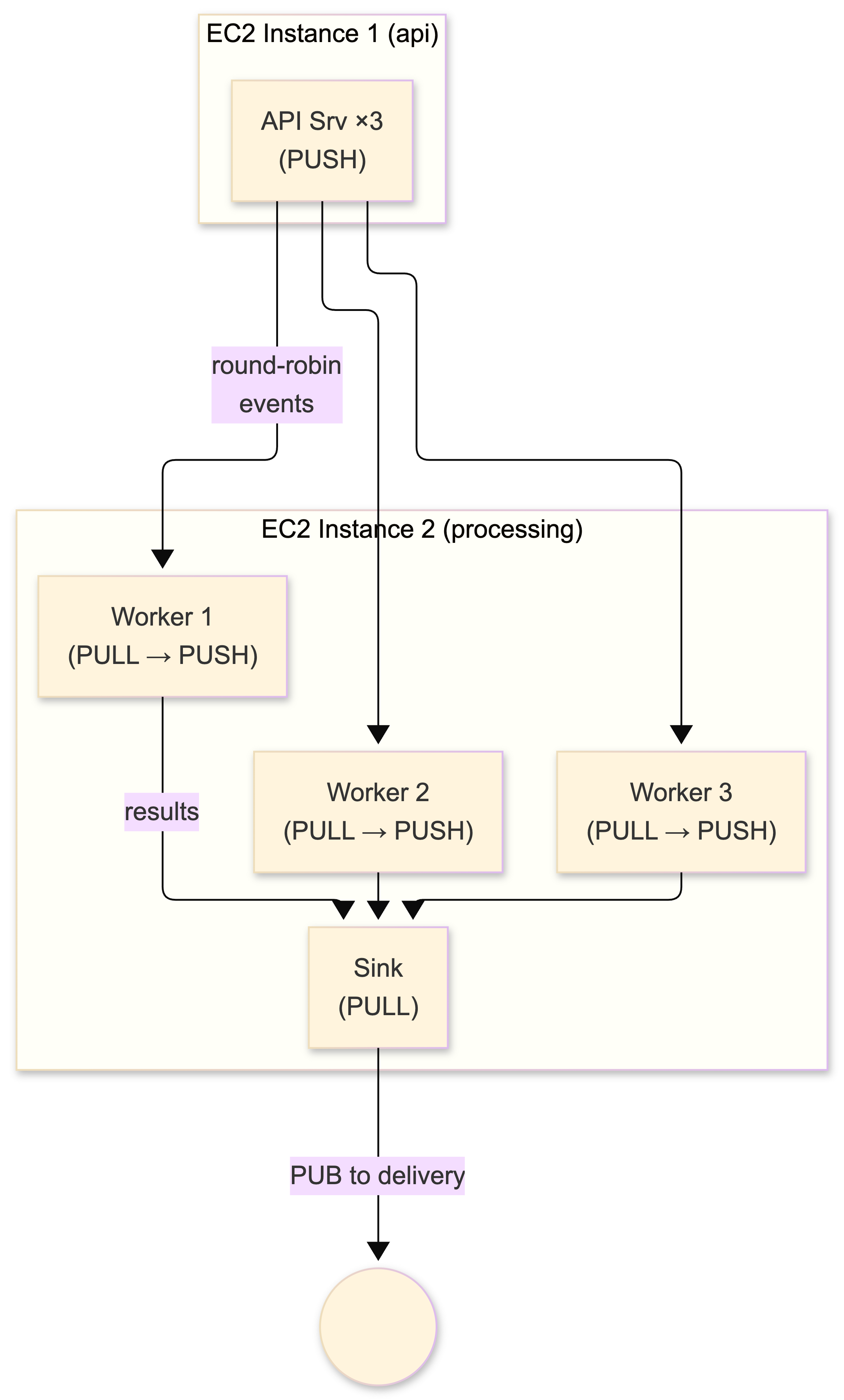
One caveat I hit early: PUSH starts round-robining the moment a peer connects. If you start one worker first, it gets a flood of queued messages before the others come online. In our PM2 cluster setup, all workers start within a second of each other so this is negligible, but if you're starting workers manually, either add synchronization or accept the brief imbalance.
I use this pattern extensively. Telemetry comes in via the PUSH/PULL fan-in, lands in parallel workers for processing (deduplication, enrichment, transformation), then results get published out. Works on a single box. Works across five boxes. Same code.
DEALER/ROUTER - the async backbone
DEALER and ROUTER are the unrestricted, asynchronous versions of REQ and REP. DEALER is an async REQ - it sends and receives without the lock-step constraint. ROUTER is an async REP - it tracks every connection with an identity frame and enables explicit routing to specific peers.
When ROUTER receives a message, it prepends an identity frame identifying the sender. When you send through ROUTER, you provide the identity first and ROUTER routes to that specific peer. This identity-based routing is the foundation of every advanced ZeroMQ architecture.
The classic broker pattern:
broker.js
// broker.js - ROUTER/DEALER proxy
var zmq = require('zmq');
var frontend = zmq.socket('router');
frontend.bind('tcp://*:5559');
var backend = zmq.socket('dealer');
backend.bind('tcp://*:5560');
// Forward traffic between frontend and backend
frontend.on('message', function() {
var args = Array.prototype.slice.call(arguments);
backend.send(args);
});
backend.on('message', function() {
var args = Array.prototype.slice.call(arguments);
frontend.send(args);
});
console.log('ROUTER/DEALER broker running on 5559/5560');In Node.js the multipart message handling uses variadic arguments - each frame arrives as a separate argument to the callback. The arguments spread pattern above is the idiomatic way to forward multipart messages through a proxy.
Critical gotcha: ROUTER silently drops messages sent to identities it doesn't recognize. Peer disconnected? Message gone. No error. No 'error' event. Nothing. Set the ZMQ_ROUTER_MANDATORY option to get actual errors:
frontend.setsockopt(zmq.ZMQ_ROUTER_MANDATORY, 1);
// Now unroutable messages emit an error instead of vanishingI set this on every ROUTER socket immediately after creation. The default behavior - silent message loss - is insane for anything resembling production. I burned two full days debugging a message-eating bug before discovering this. Two days.
PAIR - thread signaling, nothing more
PAIR sockets create an exclusive connection between two endpoints. Designed for inter-thread coordination over inproc:// transport. In Node.js, since we're single-threaded (with the event loop), PAIR is mainly useful for coordinating with worker threads or child processes over IPC. I don't use it much in our system, but it's there if you need it.
Don't use PAIR over TCP. No auto-reconnect. No multi-peer. It's a signaling primitive.
XPUB/XSUB - the proxy you actually need
XPUB and XSUB are "raw" PUB/SUB that expose subscription events to your application. Their primary use: building an intermediary proxy that solves the dynamic discovery problem.
Without a proxy, every publisher needs to know every subscriber's address. With XSUB/XPUB, everyone connects to one well-known endpoint. Publishers connect to XSUB, subscribers connect to XPUB. The proxy forwards data and subscription commands.
This is what runs on our processing tier:
proxy.js
// proxy.js - the central nervous system (EC2 instance 2)
var zmq = require('zmq');
var xsub = zmq.socket('xsub');
xsub.bind('tcp://*:5559'); // Internal publishers connect here
var xpub = zmq.socket('xpub');
xpub.bind('tcp://*:5560'); // Subscribers connect here
// Forward data and subscriptions bidirectionally
xsub.on('message', function(data) {
xpub.send(data);
});
xpub.on('message', function(data) {
xsub.send(data); // Forward subscription commands
});
console.log('XSUB/XPUB proxy: pub→5559, sub→5560');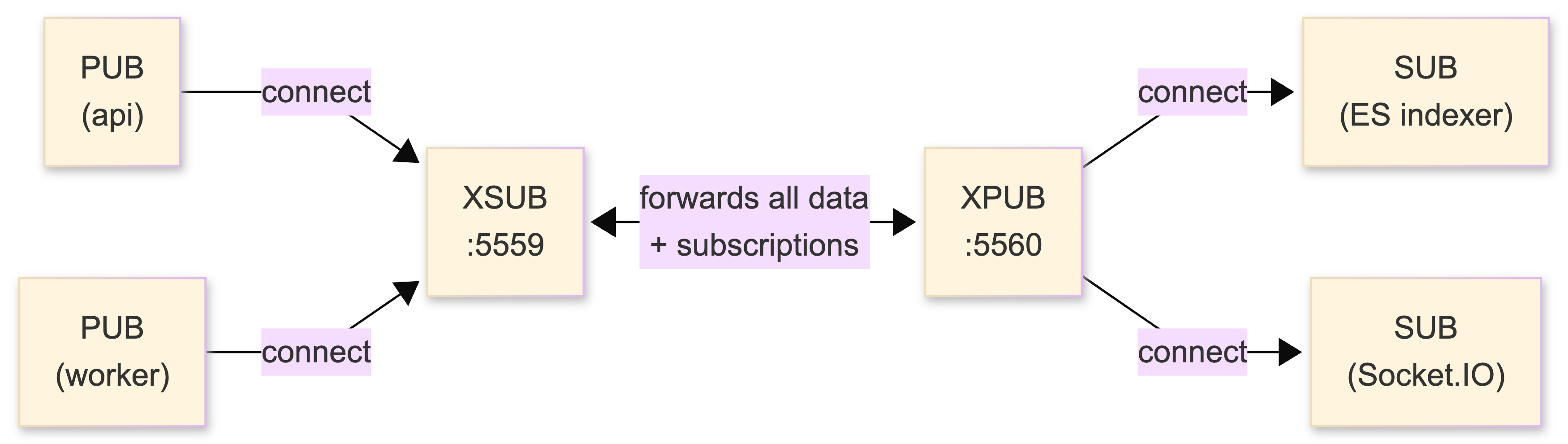
New service comes online? Just connect to the proxy. No configuration change. No restart. Nothing.
This is the piece that makes the whole architecture elastic. When I add a new consumer - say, a webhook dispatcher - it connects to the proxy and subscribes. No code changes on the publisher side. No config files. No restart. On EC2, when an Auto Scaling event spins up a new API server, it connects to the proxy's private IP and starts pushing events immediately.
How the pieces fit together: our architecture
Let me map ZeroMQ patterns to the actual system, because this is where it clicks:
Stage 1 - Event Ingestion (PUSH/PULL)
Multiple Node.js API servers (PM2 cluster, 3 workers each on EC2 instance 1) generate events from Express route handlers. Each worker has a PUSH socket connected to the processing tier. PUSH round-robins across connected PULL workers, providing automatic load balancing.
Stage 2 - Processing Pipeline (PULL → transform → PUB)
Workers on EC2 instance 2 PULL events from the ingestion stage, perform enrichment (lookup user data from Redis cache), deduplication (in-memory LRU set with a 60-second TTL), and transformation (normalization, derived fields). Processed events are published via PUB through the XPUB/XSUB proxy.
Stage 3a - Elasticsearch Indexing (SUB → bulk index)
The ES indexer on EC2 instance 3 subscribes to all events (""), buffers them, and bulk-indexes into Elasticsearch every 500ms or every 100 events, whichever comes first. ES bulk indexing is vastly more efficient than individual document inserts - this single optimization took our indexing throughput from ~200 events/sec to ~8,000 events/sec.
Stage 3b - Real-Time Delivery (SUB → Socket.IO)
The Socket.IO bridge on EC2 instance 3 subscribes to notification-type events and fans them out to connected browser clients. More detail on this integration below.
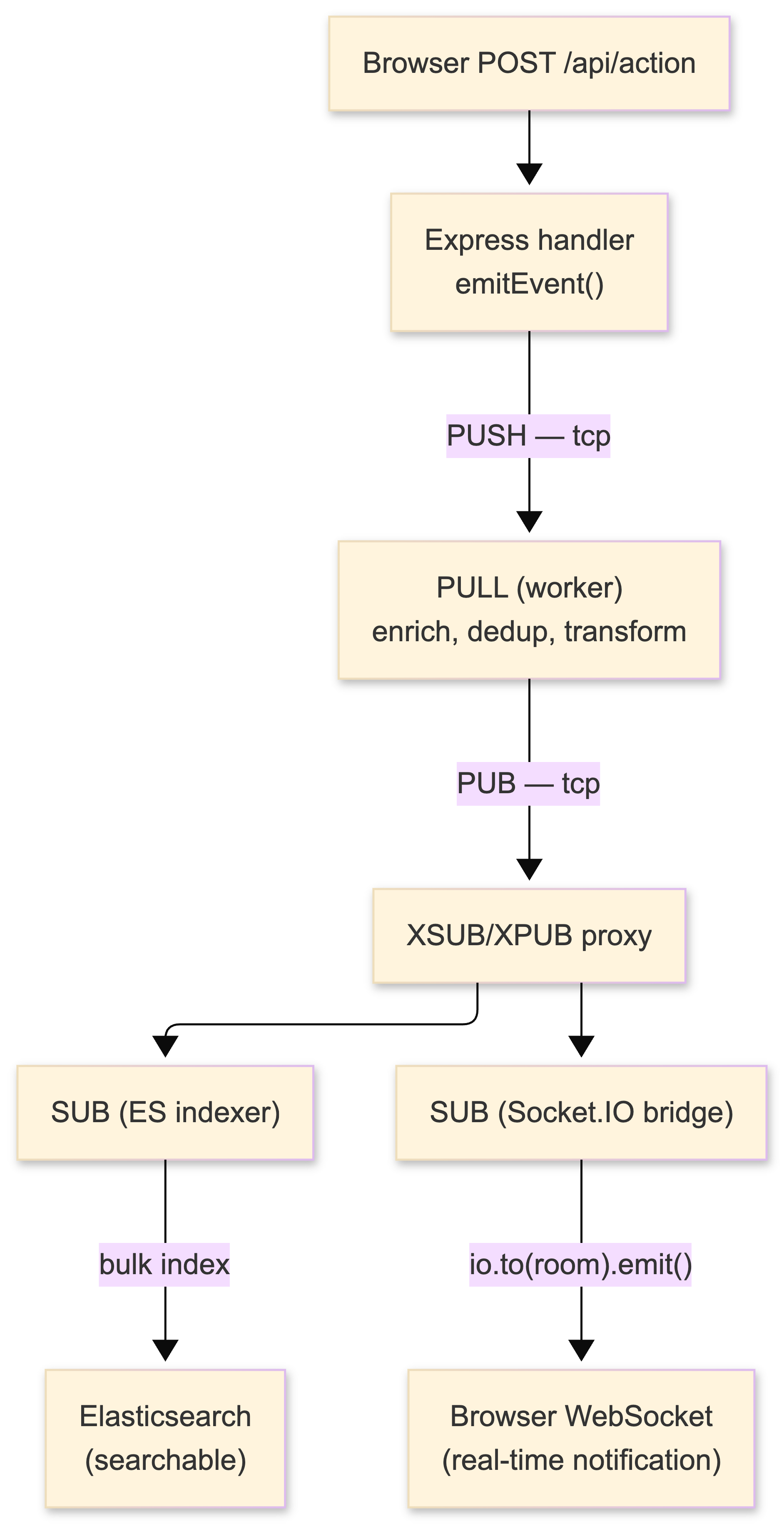
Total latency: 3–8 ms end-to-end (measured in production with timestamp deltas)
Architecture and internals that matter
The context model
Every ZeroMQ application begins with a context. In Node.js this is implicit - the zmq module manages it - but understanding it matters. The context owns background I/O threads that handle all actual network operations asynchronously. Default: 1 I/O thread, sufficient for most applications. Rule of thumb from the zguide: one I/O thread per gigabyte of data per second.
The critical rule: sockets are NOT thread-safe. In Node.js, this is somewhat less of a concern since you're mostly single-threaded, but if you're using cluster module or child processes, each process needs its own sockets. Never, ever share a ZeroMQ socket across a fork boundary. I've seen this go wrong in other projects - the failure mode is not a crash, it's random silent corruption and intermittent hangs that make you question your sanity. One socket per execution context. Period.
Message framing and multipart messages
ZeroMQ delivers discrete, length-prefixed binary blobs. No parsing. No delimiters. No partial reads. In Node.js, each message arrives as a Buffer in the 'message' callback - complete, every time.
Messages can be multipart: multiple frames sent with the ZMQ_SNDMORE flag. ZeroMQ guarantees atomicity - all frames arrive, or none. In Node.js, multipart messages arrive as separate arguments:
// Sending multipart
socket.send(['frame1', 'frame2', 'frame3']);
// Receiving multipart
socket.on('message', function(frame1, frame2, frame3) {
// Each frame is a Buffer
});This is how ROUTER identity routing works:

I serialize payloads as JSON. At our message volumes (~5K–20K events/sec peak), JSON parsing overhead is negligible compared to the actual work each event requires. If I were pushing 500K+/sec I'd switch to MessagePack or Protocol Buffers, but premature optimization is the root of all debugging sessions.
High-water marks: the silent killer
The high-water mark (HWM) is the maximum number of messages ZeroMQ queues in memory per peer. In ZeroMQ 2.x, the default was 0 (unlimited) - a beautiful way to OOM-kill your EC2 instance at 3 AM. Starting with 3.x, the default changed to 1000 messages for both ZMQ_SNDHWM and ZMQ_RCVHWM.
What happens at HWM depends on socket type:
| Behavior | Socket Types | What Happens |
|---|---|---|
| DROP | PUB, ROUTER, XPUB | Messages silently disappear. Zero notification. |
| BLOCK | PUSH, DEALER, REQ, PAIR | zmq_send() blocks until the queue drains. In Node.js, BLOCK means the send call blocks the event loop. Bad. |
The BLOCK behavior on PUSH sockets is something to watch in Node.js. If downstream workers are slow and the HWM fills, socket.send() blocks synchronously - which blocks the Node.js event loop. Your Express server stops responding to HTTP requests. I set generous HWM values on PUSH sockets and monitor queue depth to catch this before it becomes a problem:
var pusher = zmq.socket('push');
pusher.setsockopt(zmq.ZMQ_SNDHWM, 50000); // 50K message buffer
pusher.connect('tcp://10.0.1.20:5557');Transport protocols: tcp, ipc, inproc, pgm
All transports use the same socket API:
tcp:// - Everything across EC2 instances. Handles reconnection, buffering, Nagle toggling internally. Use private IPs within the VPC: tcp://10.0.1.20:5557.
ipc:// - Unix domain sockets for processes on the same instance. Faster than TCP (no network stack). I use this between the Socket.IO bridge and the ES indexer on instance 3, since they're co-located.
socket.bind('ipc:///tmp/event-feed.ipc'); // Server-side
socket.connect('ipc:///tmp/event-feed.ipc'); // Client-sideinproc:// - Direct memory transfer between threads sharing a context. Sub-microsecond. Less relevant in Node.js single-threaded land, but useful if you're using native addons with threads.
pgm:// and epgm:// - IP multicast for one-to-many PUB/SUB. Niche but devastating when you need it. We don't use it - our subscriber count is small enough that unicast TCP is fine.
| Transport | Typical Latency | Notes |
|---|---|---|
inproc:// | < 1 μs | Memory copy |
ipc:// | ~10–15 μs | Unix domain socket |
tcp:// (localhost) | ~25–30 μs | Loopback TCP |
tcp:// (same AZ) | ~200–500 μs | Network + TCP |
tcp:// (cross-AZ) | ~500–2000 μs | Depends on AZ pair |
Reliability patterns: the stuff that keeps you employed
Raw patterns lose messages. PUB/SUB drops by design. PUSH/PULL has no acknowledgment. REQ/REP hangs on server failure. ZeroMQ gives you performance; reliability is your job. The zguide (Chapter 4) builds it up progressively. These are the four patterns I care about.
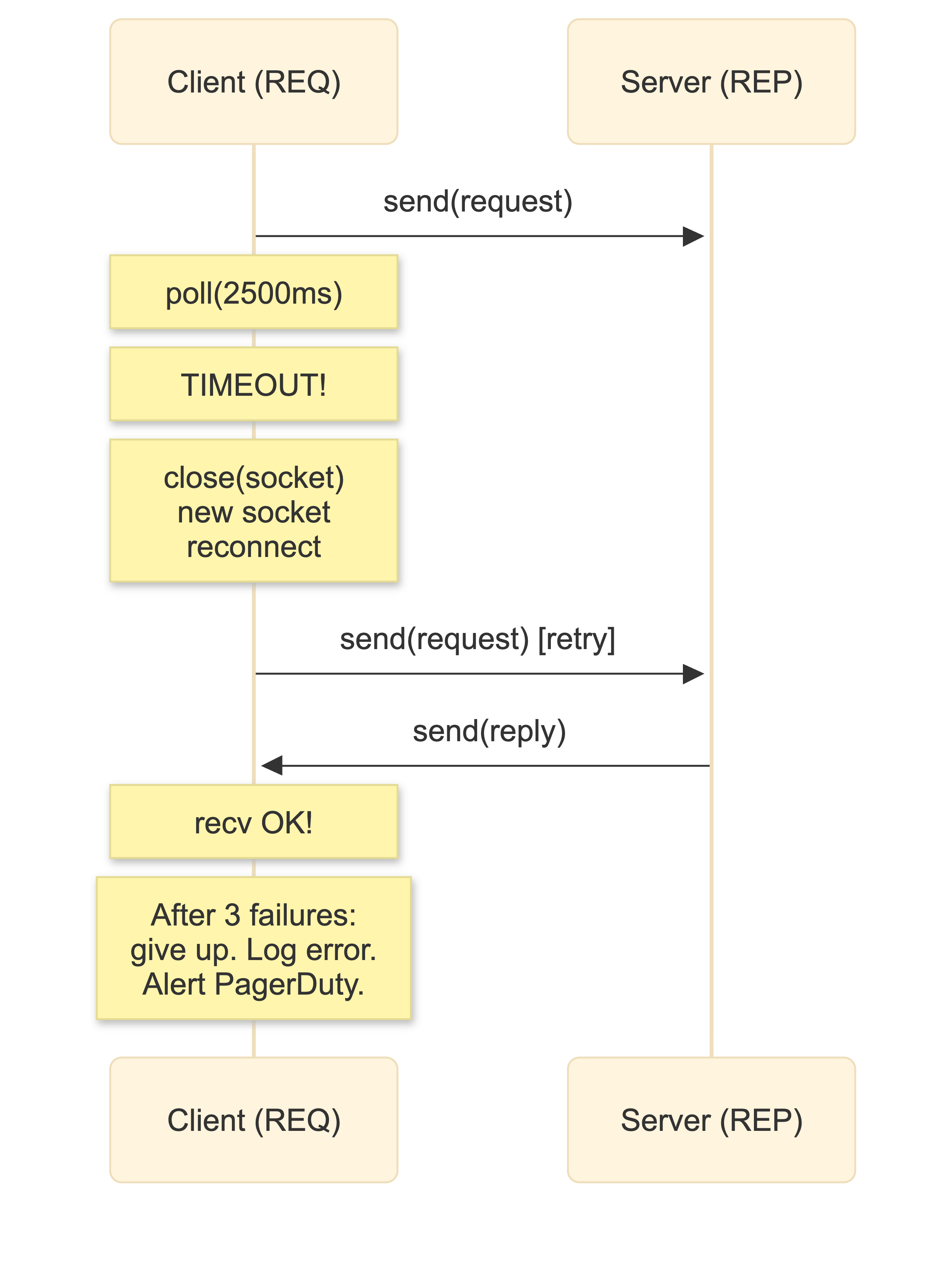
Lazy Pirate: client-side retry
Adds timeout and retry logic to REQ/REP. After sending, the client polls with a timeout. No reply? Destroy the socket (critical - a stuck REQ state machine cannot be reset), create a new one, reconnect, resend. After N failures, give up.
lazy-pirate-client.js
// lazy-pirate-client.js
var zmq = require('zmq');
var TIMEOUT = 2500; // ms
var RETRIES = 3;
var ENDPOINT = 'tcp://10.0.1.20:5555';
function createSocket() {
var s = zmq.socket('req');
s.connect(ENDPOINT);
return s;
}
var client = createSocket();
var sequence = 0;
function sendRequest() {
var request = String(sequence);
client.send(request);
var retries = RETRIES;
var timer = setTimeout(function retry() {
retries--;
if (retries === 0) {
console.error('Server offline, abandoning');
client.close();
return;
}
console.log('No response, reconnecting...');
client.setsockopt(zmq.ZMQ_LINGER, 0);
client.close();
// CRITICAL: destroy and recreate the socket
client = createSocket();
client.on('message', handleReply);
client.send(request);
timer = setTimeout(retry, TIMEOUT);
}, TIMEOUT);
function handleReply(msg) {
clearTimeout(timer);
if (msg.toString() === request) {
console.log('Server replied OK: ' + msg);
sequence++;
process.nextTick(sendRequest);
}
}
client.on('message', handleReply);
}
sendRequest();The essential insight: you must destroy and recreate the socket after a timeout. The REQ state machine is stuck. There's no reset API. There's no timeout option. You close it, make a new one, and move on. The overhead is negligible compared to the cost of a hung connection.
Paranoid Pirate: heartbeating that works
Extends Lazy Pirate with a broker between clients and workers, plus bidirectional heartbeating for worker liveness detection. The broker (ROUTER/ROUTER) tracks live workers and dispatches on an LRU basis. Workers use DEALER (not REP - DEALER allows interleaving heartbeats with request processing). Workers send periodic heartbeat signals; if they miss N intervals, the broker purges them. Workers detect broker death via missing heartbeats and reconnect with exponential backoff.
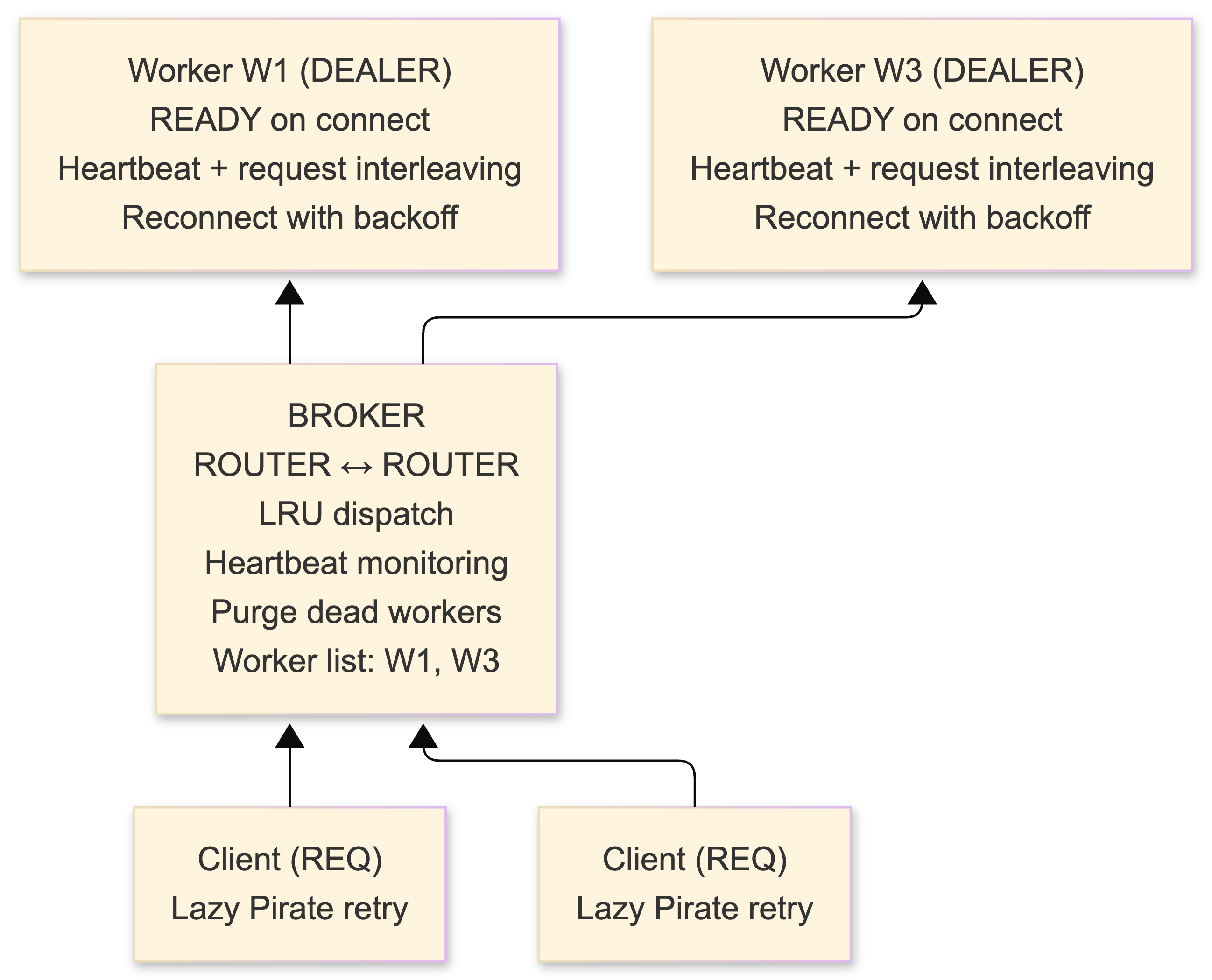
This is the minimum viable reliability pattern for multi-worker systems where you can't afford dropped requests. I haven't needed it for our event pipeline (PUSH/PULL with monitoring handles our throughput), but I've implemented it for the request-reply service tier where lost requests are unacceptable.
Majordomo: service-oriented routing
Majordomo Protocol (MDP, formally specified as RFC 7/MDP at rfc.zeromq.org) extends Paranoid Pirate with named service routing. Workers register under a service name ("notify", "enrich", "transform"). Clients specify which service they want. The broker routes to an available worker for that service.
The protocol defines MDPC01 (client↔broker) and MDPW01 (worker↔broker) with explicit commands: READY, REQUEST, REPLY, HEARTBEAT, DISCONNECT. The broker also exposes mmi.* internal services - send mmi.service with a service name, get back "200" (available) or "404" (not registered). Service discovery baked into the messaging protocol. No Consul. No etcd. No external service registry.
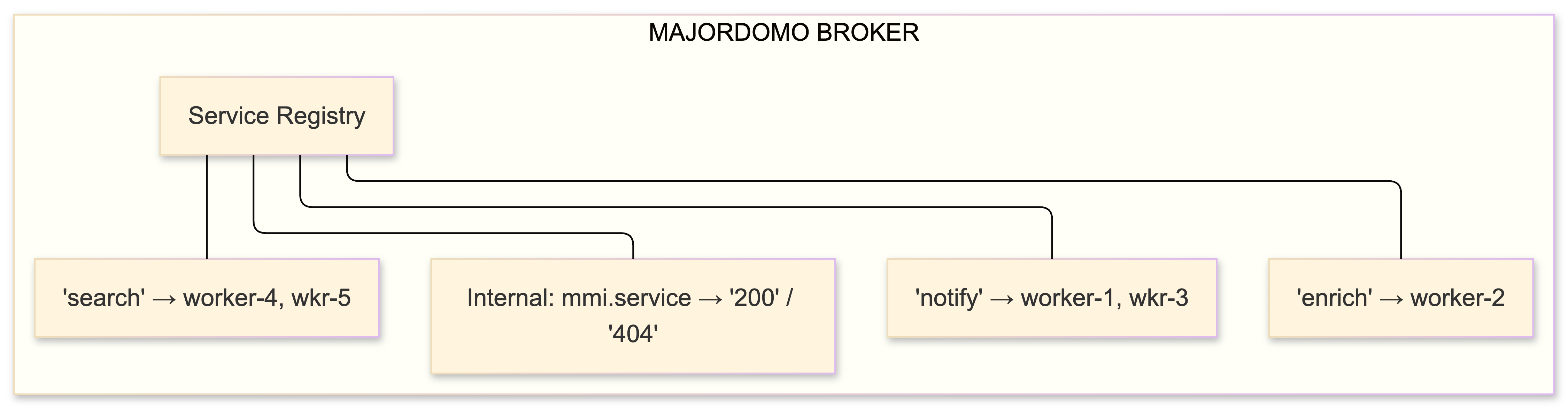
I haven't deployed MDP yet - Paranoid Pirate covers my current needs. But it's on the roadmap for when we split the processing pipeline into independently scalable named services.
Clone: distributed state replication
The Clone pattern solves distributing a shared key-value store with reliable late-joiner support. The zguide builds this through six progressive versions:
- Server publishes K-V updates on PUB; clients subscribe
- Sequence numbers for gap detection
- Snapshot mechanism: new clients request full state via DEALER→ROUTER, then subscribe to live updates starting after the snapshot's sequence number
- Bidirectional: clients submit changes via PUSH→PULL
- Subtree subscriptions and TTL-based ephemeral values
- Binary Star failover for HA
The snapshot request uses "ICANHAZ?" with "KTHXBAI" marking the end of the state dump. Peak Hintjens.
I don't use Clone directly, but the snapshot concept influenced how our Socket.IO bridge handles reconnection: when a browser reconnects, it sends the last-seen sequence number and we replay missed events from a short Redis buffer. Same principle, different implementation.
Deploying on AWS EC2 - the full walkthrough
Instance sizing and layout
Our production deployment runs on three EC2 instances in the same AZ (us-east-1a). Cross-AZ would add latency; we accept the single-AZ risk and rely on AMIs plus CloudFormation for recovery.

Monthly cost: 3 × t2.medium = 3 × ~$38 = ~$114/month (On-demand pricing, us-east-1, Nov 2015). With reserved instances: ~$70/month.
Yes, Elasticsearch is on the same instance as the Socket.IO server. I know. In a bigger deployment these would be separate. But the ES JVM heap is capped at 2 GB, the indexer is I/O-bound not CPU-bound, and the Socket.IO server is mostly idle between bursts. It works. When it stops working, I'll split them.
Building ZeroMQ on Ubuntu 14.04
Ubuntu 14.04's repos ship libzmq3-dev (the 3.2.x series). For 4.x with CURVE security support, build from source:
#!/bin/bash
# install-zeromq-ec2.sh
# Tested on Ubuntu 14.04.3 LTS, t2.medium
set -e
# Build dependencies
sudo apt-get update
sudo apt-get install -y libtool pkg-config build-essential autoconf automake uuid-dev
# libsodium (required for CURVE encryption)
cd /tmp
wget https://download.libsodium.org/libsodium/releases/libsodium-1.0.3.tar.gz
tar -xvf libsodium-1.0.3.tar.gz
cd libsodium-1.0.3
./configure
make -j$(nproc)
make check
sudo make install
sudo ldconfig
cd /tmp
# ZeroMQ 4.1.4
wget http://download.zeromq.org/zeromq-4.1.4.tar.gz
tar -xvf zeromq-4.1.4.tar.gz
cd zeromq-4.1.4
./configure --with-libsodium
make -j$(nproc)
make check
sudo make install
sudo ldconfig
echo "Installed: $(pkg-config --modversion libzmq)"
# Should print: 4.1.4The --with-libsodium flag is important. Without it, CURVE is silently disabled - no error, no warning, just no encryption. I burned an hour figuring out why CURVE handshakes were failing before I realized libzmq was compiled without sodium support. Check with ldd /usr/local/lib/libzmq.so | grep sodium.
I bake this into a Packer AMI template so every new instance comes with ZeroMQ pre-installed. CloudFormation launches from the AMI, UserData runs npm install, PM2 starts the processes. Full deployment from git push to running takes under 4 minutes.
Node.js and the zmq binding
# Requires: libzmq headers installed (from build above)
npm install zmq
# Verify
node -e "var zmq = require('zmq'); console.log('ZMQ version: ' + zmq.version);"
# Should print: ZMQ version: 4.1.4The zmq npm package (version 2.x in 2015) compiles a native addon via node-gyp against your system's libzmq. This means:
- You need
build-essential,python2.7, and libzmq headers atnpm installtime - If you upgrade libzmq, rebuild with
npm rebuild zmq - If deploying to a different OS/architecture than you develop on, install on the target (don't copy
node_modules)
I pin the zmq version in package.json and include a postinstall check:
{
"dependencies": {
"zmq": "~2.15.3",
"socket.io": "~1.3.7",
"elasticsearch": "~8.2.0",
"express": "~4.13.3",
"jsonwebtoken": "~5.4.1"
},
"scripts": {
"postinstall": "node -e \"require('zmq')\" || echo 'ZMQ NATIVE MODULE FAILED'",
"start": "pm2 start ecosystem.json"
}
}Security groups and port management
ZeroMQ uses plain TCP. Your EC2 security groups need to allow the specific ports between instances:
Security Group: sg-zmq-internal (applied to all three instances):
| Type | Protocol | Port Range | Source |
|---|---|---|---|
| Custom TCP | TCP | 5555-5565 | sg-zmq-internal |
| Custom TCP | TCP | 6379 | sg-zmq-internal (Redis) |
| Custom TCP | TCP | 9200 | sg-zmq-internal (ES) |
| Custom TCP | TCP | 9300 | sg-zmq-internal (ES) |
Security Group: sg-public-facing (applied to instance 1 + instance 3):
| Type | Protocol | Port Range | Source |
|---|---|---|---|
| HTTPS | TCP | 443 | 0.0.0.0/0 (ELB) |
| Custom TCP | TCP | 3000 | ELB security group |
Always use private IPs for ZeroMQ sockets within the VPC. Never bind to 0.0.0.0 in production:
socket.bind('tcp://10.0.1.20:5557'); // Good: private IP only
// NOT: socket.bind('tcp://*:5557'); // Bad: all interfaces including publicProcess management with upstart and systemd
On Ubuntu 14.04, I use PM2 for the Node.js processes and upstart to manage PM2 itself:
// ecosystem.json (PM2 config)
{
"apps": [
{
"name": "api-server",
"script": "./server.js",
"instances": 3,
"exec_mode": "cluster",
"env": {
"NODE_ENV": "production",
"ZMQ_PROCESSING_HOST": "tcp://10.0.1.20:5557"
}
},
{
"name": "zmq-proxy",
"script": "./proxy.js",
"instances": 1,
"env": {
"NODE_ENV": "production"
}
},
{
"name": "event-worker",
"script": "./worker.js",
"instances": 2,
"env": {
"NODE_ENV": "production",
"ZMQ_PROXY_XSUB": "tcp://10.0.1.20:5559",
"ZMQ_PROXY_XPUB": "tcp://10.0.1.20:5560"
}
},
{
"name": "es-indexer",
"script": "./es-indexer.js",
"instances": 1,
"env": {
"NODE_ENV": "production",
"ES_HOST": "http://localhost:9200",
"ZMQ_PROXY_XPUB": "tcp://10.0.1.20:5560"
}
},
{
"name": "socketio-bridge",
"script": "./socketio-bridge.js",
"instances": 1,
"env": {
"NODE_ENV": "production",
"ZMQ_PROXY_XPUB": "tcp://10.0.1.20:5560"
}
}
]
}# Start everything
pm2 start ecosystem.json
# Save the process list (survives reboot via upstart)
pm2 save
pm2 startup upstart
# Monitor in real-time
pm2 monitIf you're on a newer Ubuntu with systemd, a unit file works too:
# /etc/systemd/system/zmq-proxy.service
[Unit]
Description=ZeroMQ XPUB/XSUB Proxy
After=network.target
[Service]
Type=simple
User=app
WorkingDirectory=/opt/app
ExecStart=/usr/bin/node /opt/app/proxy.js
Restart=on-failure
RestartSec=3s
Environment=NODE_ENV=production
Environment=LD_LIBRARY_PATH=/usr/local/lib
[Install]
WantedBy=multi-user.targetMonitoring ZeroMQ in production
No management UI. That's the tradeoff. You monitor with the same tools you use for everything else:
Application-level metrics: I push to StatsD → Graphite (running on a separate t2.micro):
// In every ZeroMQ-connected process
var StatsD = require('node-statsd');
var statsd = new StatsD({ host: '10.0.1.40' });
receiver.on('message', function(data) {
statsd.increment('zmq.events.received');
var event = JSON.parse(data);
statsd.timing('zmq.events.latency', Date.now() - event.timestamp);
// ... process ...
});Socket lifecycle logging: Connection, disconnection, and retry events as structured JSON:
socket.on('connect', function(fd, ep) {
console.log(JSON.stringify({ event: 'zmq_connect', endpoint: ep, ts: Date.now() }));
});
socket.on('disconnect', function(fd, ep) {
console.log(JSON.stringify({ event: 'zmq_disconnect', endpoint: ep, ts: Date.now() }));
});Health checks: Dedicated REQ/REP endpoint per service. Sensu sends "PING", expects "PONG" within 3 seconds.
Wiring Socket.IO to the ZeroMQ backbone
The Socket.IO bridge is the most elegant part of this architecture. Here's the full production version:
// socketio-bridge.js
var http = require('http');
var socketio = require('socket.io');
var zmq = require('zmq');
var jwt = require('jsonwebtoken');
var server = http.createServer();
var io = socketio(server, {
transports: ['websocket', 'polling'],
pingInterval: 25000,
pingTimeout: 60000
});
// ZeroMQ subscriber - connects to XPUB proxy
var sub = zmq.socket('sub');
sub.connect(process.env.ZMQ_PROXY_XPUB || 'tcp://10.0.1.20:5560');
sub.subscribe('notification.');
sub.subscribe('alert.');
sub.subscribe('status.');
var connectedUsers = {};
// JWT authentication middleware
io.use(function(socket, next) {
var token = socket.handshake.query.token;
try {
socket.decoded = jwt.verify(token, process.env.JWT_SECRET);
next();
} catch (err) {
next(new Error('Authentication failed'));
}
});
io.on('connection', function(socket) {
var userId = socket.decoded.userId;
socket.join('user:' + userId);
connectedUsers[userId] = (connectedUsers[userId] || 0) + 1;
socket.on('disconnect', function() {
connectedUsers[userId]--;
if (connectedUsers[userId] <= 0) delete connectedUsers[userId];
});
// Client requests missed events since last seen sequence
socket.on('sync', function(lastSeq, callback) {
replayFromRedis(userId, lastSeq, function(events) {
callback(events);
});
});
});
// Bridge: ZeroMQ events → Socket.IO rooms
sub.on('message', function(data) {
var str = data.toString();
var spaceIdx = str.indexOf(' ');
var topic = str.slice(0, spaceIdx);
var payload;
try {
payload = JSON.parse(str.slice(spaceIdx + 1));
} catch (e) {
console.error('Failed to parse ZMQ message:', e);
return;
}
var parts = topic.split('.');
var eventType = parts[0];
var userId = parts[1];
// Only emit if user is actually connected (save CPU on io.to)
if (userId && connectedUsers[userId]) {
io.to('user:' + userId).emit(eventType, payload);
}
// Broadcast events go to everyone
if (userId === '*') {
io.emit(eventType, payload);
}
});
var PORT = process.env.PORT || 3001;
server.listen(PORT, function() {
console.log('Socket.IO bridge listening on ' + PORT);
});The key optimization: checking connectedUsers[userId] before calling io.to().emit(). Socket.IO room emit isn't free - skipping it entirely for offline users saves measurable CPU when you're handling thousands of events per second but only hundreds of users are connected at any given moment.
The sync handler lets clients request events they missed during a disconnect. We keep a 5-minute Redis sorted set per user, scored by sequence number. Not as elegant as ZeroMQ's Clone pattern, but simpler and sufficient.
Feeding Elasticsearch from the pipeline
The ES indexer is straightforward but has one crucial optimization - bulk indexing:
// es-indexer.js
var zmq = require('zmq');
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: process.env.ES_HOST || 'localhost:9200',
log: 'warning'
});
var sub = zmq.socket('sub');
sub.connect(process.env.ZMQ_PROXY_XPUB || 'tcp://10.0.1.20:5560');
sub.subscribe(''); // ALL events
var buffer = [];
var FLUSH_SIZE = 100;
var FLUSH_INTERVAL = 500; // ms
sub.on('message', function(data) {
var str = data.toString();
var spaceIdx = str.indexOf(' ');
var payload;
try {
payload = JSON.parse(str.slice(spaceIdx + 1));
} catch (e) { return; }
buffer.push({ index: { _index: 'events-' + todayStr(), _type: 'event' } });
buffer.push(payload);
if (buffer.length >= FLUSH_SIZE * 2) {
flush();
}
});
setInterval(function() {
if (buffer.length > 0) flush();
}, FLUSH_INTERVAL);
function flush() {
var body = buffer.splice(0);
if (body.length === 0) return;
client.bulk({ body: body }, function(err, resp) {
if (err) {
console.error('ES bulk index error:', err);
// Events lost on failure. Acceptable for our use case.
// For guaranteed indexing: WAL file + retry.
}
});
}
function todayStr() {
var d = new Date();
return d.getFullYear() + '.' +
('0' + (d.getMonth() + 1)).slice(-2) + '.' +
('0' + d.getDate()).slice(-2);
}Bulk indexing was the single biggest performance win. Individual inserts to ES maxed out around 200/sec due to per-request overhead. Bulk batches of 100 documents get us to 8,000+ events/sec sustained. The daily index pattern (events-2015.11.17) enables easy rotation - we keep 30 days, then delete old indices with a cron job.
Performance numbers from our actual deployment
Real numbers. Measured with timestamp deltas embedded in every event:
End-to-end latency (event generation → browser notification):
| Percentile | Latency |
|---|---|
| p50 (median) | 4.2 ms |
| p95 | 8.7 ms |
| p99 | 14.3 ms |
| p99.9 (worst during load spikes) | 42 ms |
Throughput:
| Metric | Value |
|---|---|
| Sustained event rate (typical) | 2K–5K/sec |
| Peak burst rate (handled without loss) | ~20K/sec |
| ES bulk indexing rate | 8K/sec |
| Socket.IO concurrent connections | ~2,000 |
| PUB/SUB message fan-out per event | 2–3 subs |
Resource usage across all three t2.medium instances:
| Resource | Usage |
|---|---|
| Total RAM used (all 3 instances) | ~6.5 GB |
| ZeroMQ memory overhead (all processes) | ~25 MB |
| CPU utilization (typical) | 15–30% |
| CPU utilization (peak bursts) | 60–75% |
| Network bandwidth (inter-instance) | 2–10 Mbps |
For reference, published ZeroMQ benchmarks show ~6.2 million msgs/sec for small messages over TCP in C. We're nowhere near that ceiling - our bottleneck is JSON parsing and Elasticsearch indexing, not ZeroMQ. The messaging layer is invisible in our flame graphs. That's exactly what you want.
Who else is running ZeroMQ in production
Not just hobbyists:
Jupyter/IPython - The notebook communicates between kernels and frontends over five ZeroMQ sockets: Shell (ROUTER), IOPub (PUB), stdin (ROUTER), Control (ROUTER), Heartbeat (REP). If you use Jupyter, you use ZeroMQ.
SaltStack - Default transport for master→minion communication. PUB/SUB for commands, REQ/REP for auth and returns. Manages tens of thousands of nodes with sub-second command execution.
Spotify - Built Hermes, an internal messaging stack on ZeroMQ + protobuf + gevent for backend service communication.
OpenStack - oslo.messaging supports ZeroMQ as an alternative to RabbitMQ.
CERN - Uses ZeroMQ via FairMQ in the ALICE experiment's data acquisition pipeline. When particle physicists at CERN need messaging for detector data, they use this.
Samsung, AT&T, Facebook, DigitalOcean, and Auth0 are also listed as users. This is production-grade infrastructure.
Seven things that will bite you
I've hit all of these. Learn from my weekends.
1. The slow subscriber eats your memory then drops your messages
PUB/SUB has zero back-pressure. Publisher sends at full speed. Slow subscriber queues until HWM, then messages drop silently. No error event. No callback.
Mitigation: application-level sequence numbers with gap detection, the Suicidal Snail pattern (subscribers detect they've fallen behind and restart), or simply accepting the loss and designing around it. I use sequence numbers plus a periodic consistency check against Elasticsearch.
2. Late joiners miss the first messages - always
Start subscriber, start publisher. Subscriber misses initial messages. Connection establishment is asynchronous. There's a non-zero window where the publisher is sending and the subscriber isn't yet connected.
Fix: synchronize via a separate REQ/REP channel before the publisher starts sending, or accept initial loss and design with sequence numbers.
3. Socket sharing across processes = silent corruption
In Node.js with PM2 cluster mode: each worker process gets its own sockets. Do not create a socket in the master and expect it to work in forked workers. The failure mode isn't a crash - it's silent data corruption and intermittent hangs. Each PM2 worker creates its own PUSH socket in its own process scope.
4. The LINGER default hangs your shutdown
ZMQ_LINGER defaults to -1 (infinite wait). Context teardown blocks forever flushing pending messages. Your Node.js process hangs on SIGTERM and your deploy stalls waiting for the old process to die.
// Graceful shutdown - EVERY ZeroMQ Node.js service needs this
process.on('SIGTERM', function() {
console.log('Shutting down...');
[pusher, sub, pub].forEach(function(s) {
if (s) {
s.setsockopt(zmq.ZMQ_LINGER, 0);
s.close();
}
});
server.close(function() { process.exit(0); });
});5. Message loss is a feature, not a bug
ZeroMQ loses messages in at least five scenarios: subscription propagation delay, HWM overflow, no persistence (offline peers miss everything), network failure during reconnection, and process crash with messages in the send buffer. If you need guaranteed delivery, you build it yourself. ZeroMQ gives you speed; guarantees are your problem.
6. Enable ROUTER_MANDATORY immediately
ROUTER silently drops messages to unknown identities by default. Set ZMQ_ROUTER_MANDATORY on every ROUTER socket. Two days I lost to this bug. Two days.
7. Node.js PUSH blocking the event loop
When a PUSH socket's HWM fills because downstream consumers are slow, socket.send() blocks synchronously. In Node.js, this blocks the event loop - your Express server stops responding. Set generous HWM values and monitor queue depth. Consider checking socket writability before sending on critical paths.
ZeroMQ vs. the alternatives: when to use what
| Brokerless Libraries | Traditional Brokers | Log-based Systems | |
|---|---|---|---|
| Examples | ZeroMQ, nanomsg | RabbitMQ, ActiveMQ | Kafka |
| Throughput | Millions/sec | 10K–50K/sec | 100K+/sec |
| Latency | μs range | ms range | ms range |
| Persistence | None | Yes | Yes (disk) |
| Guaranteed delivery | Build it yourself | Built-in (ACKs) | Built-in (offsets) |
| Infra overhead | Zero (library) | Broker + deps | ZK + brokers |
| Memory cost | 3–5 MB | 500 MB–1 GB | 1+ GB (JVM) |
| Best for | Real-time, low-latency, tight budget | Complex routing, guaranteed delivery | Event sourcing, stream replay, big data |
nanomsg by Martin Sustrik (ZeroMQ co-creator) is worth evaluating if starting fresh. Cleaner API, MIT license, adds SURVEY and BUS patterns. Comparable performance. But the ecosystem is still thinner.
My decision tree: budget allows dedicated broker infrastructure + need guaranteed delivery → RabbitMQ. Need a commit log with replay → Kafka. Need speed, minimal infrastructure, and willing to build reliability yourself → ZeroMQ.
I chose ZeroMQ because I had three EC2 instances, a real-time latency requirement, and the willingness to invest engineering time instead of infrastructure money.
Architecture diagrams and socket compatibility
Socket compatibility matrix
Don't guess. Check every time:
| From \ To | REQ | REP | PUB | SUB | DEALER | ROUTER | PUSH | PULL |
|---|---|---|---|---|---|---|---|---|
| REQ | ✓ | ✓ | ||||||
| REP | ✓ | ✓ | ||||||
| PUB | ✓ | |||||||
| SUB | ✓ | |||||||
| DEALER | ✓ | ✓ | ✓ | |||||
| ROUTER | ✓ | ✓ | ✓ | |||||
| PUSH | ✓ | |||||||
| PULL | ✓ |
Wrong pairing = silent failure or ETERM. Check every time.
Port allocation map
| Port | Protocol | Instance |
|---|---|---|
| 5555 | REQ/REP health check | All |
| 5557 | PUSH/PULL event pipeline | Instance 2 |
| 5558 | PUSH/PULL worker output | Instance 2 |
| 5559 | XSUB proxy (pub input) | Instance 2 |
| 5560 | XPUB proxy (sub output) | Instance 2 |
| 5561 | PUB processed events | Instance 2 |
| 3000 | Express API (HTTP) | Instance 1 |
| 3001 | Socket.IO (WS) | Instance 3 |
| 9200 | Elasticsearch (HTTP) | Instance 3 |
| 6379 | Redis | Instance 2 |
Final thoughts
This system has been in production for four months. It's processed roughly 800 million events. The ZeroMQ layer has never been the problem. The actual problems have been: Elasticsearch running out of disk (my fault - forgot to set up index rotation initially), a Socket.IO memory leak in an older engine.io dependency (fixed by upgrading), and a Redis eviction policy misconfiguration that nuked the dedup set during a traffic spike.
The messaging layer? Silent. Invisible. Does its job. That's the highest compliment I can give infrastructure software.
Read the zguide. All of it. zguide.zeromq.org. Pieter Hintjens doesn't just teach you the API - he teaches you how to think about distributed systems. It's free, it's comprehensive, and it's the best technical writing I've encountered since Stevens' TCP/IP Illustrated.
The "zero" in ZeroMQ means zero broker, zero latency, zero administration, zero waste. In practice, it also means zero hand-holding. The patterns work. The library is battle-tested. The performance is absurd. You just have to understand what you're doing.
For our budget and our requirements, there was no better choice.
If you're facing similar challenges, let's talk.
Bring the current architecture context and delivery constraints, and we can map out a focused next step.
Book a Discovery CallNewsletter
Stay connected
Not ready for a call? Get the next post directly.