BLOG POST
Building a Chat System at Scale: Microservices Lessons
For the past year and a half, I’ve been building the real-time infrastructure that powers a social trading platform. Financial tick data. Social chat between traders. Copy-trading signals. MetaTrader 4 and MetaTrader 5 bridge integrations. Interactive Brokers connectivity. All of it flowing through the same MQTT broker cluster, delivered over WebSockets to browser and mobile clients, backed by a polyglot microservice stack on Kubernetes that we operate ourselves on bare EC2 instances.
This post is everything I wish someone had written before we started. Not the sanitized conference version where everything works on the first try, but the actual decisions - why we picked EMQTT over the alternatives, why we run our own K8s instead of waiting for EKS, how we designed MQTT topics to carry both market data and chat on the same broker, why we ended up with four languages across the backend, and the operational scars from running Erlang clusters on Kubernetes before anyone had really figured that out properly.
If you're building anything that involves persistent connections at scale, some of this will save you time. If you're running self-managed Kubernetes on AWS, a lot of this will save you from 3 AM pages.
The problem: two real-time systems that look like one
The platform is a social trading product. Think of it as a brokerage with a social layer - traders follow each other, copy trades with one click, chat in groups and DMs, and watch live market data streaming from MetaTrader servers and Interactive Brokers. From the user's perspective, it's one seamless experience. From the backend perspective, it's two fundamentally different real-time workloads crammed into the same pipe:
Financial tick data arrives from MetaTrader 4/5 servers and Interactive Brokers at hundreds of updates per second across thousands of instruments. It must reach the client's screen in under 100ms. A missed tick is irrelevant because the next one supersedes it in milliseconds. "Latest value wins" - there's no point delivering a stale price. This is fire-and-forget, high throughput, zero tolerance for latency, no delivery guarantees needed.
Social chat and notifications - group messages, direct messages, copy-trade alerts, order confirmations - have the opposite requirements. Every message must arrive. Order matters. A missed chat message is a bug. A missed trade confirmation is potentially a compliance issue. Lower throughput, but guaranteed delivery.
The naive approach is to build two separate real-time systems. WebSockets for one, a message queue for the other. But that means two connection pools per client, two authentication flows, two sets of reconnection logic, two load balancer configurations, and twice the operational surface area. We're a startup. We don't have the headcount for that.
The decision that shaped everything else: use MQTT as the unified transport for both workloads, with topic hierarchy and QoS levels handling the different delivery semantics. One broker cluster, one client connection, one protocol. MQTT's QoS system was literally designed for this - QoS 0 for ticks, QoS 1 for chat.
Why EMQTT (and why not the alternatives)
When we evaluated MQTT brokers, the landscape was straightforward:
Mosquitto - the Eclipse reference implementation. Written in C, single-threaded, no clustering. Tops out around 100K connections on generous hardware. Perfect for IoT prototypes. Completely unusable for our scale.
HiveMQ - Java-based, enterprise-grade, excellent clustering. Also commercial with enterprise pricing that made our CFO physically recoil. Not happening at our stage.
VerneMQ - Erlang/OTP like EMQTT, Apache 2.0 licensed, uses Plumtree (epidemic broadcast trees) for clustering. Solid project, but the plugin ecosystem was thinner and the authentication backends were more limited. We needed MySQL-backed auth and HTTP-based ACL checks from day one.
EMQTT v2.3 - Erlang/OTP, Apache 2.0, claimed 1M+ connections per node, native clustering via Erlang distribution, and the richest authentication plugin ecosystem of any open-source MQTT broker. MySQL auth, Redis auth, JWT auth, HTTP auth - all available as drop-in plugins. WebSocket support baked into the core, not bolted on. A built-in dashboard on port 18083 that shows connected clients, message rates, and cluster topology. And critically: Kubernetes auto-discovery for cluster formation via the Ekka library.
We went with EMQTT. Here's the honest assessment after running it in production for over a year: it's the right choice, it works, and the documentation will make you want to throw your laptop out the window because half of it was originally written in Chinese and the English translations range from adequate to cryptic. You'll spend time reading Erlang source code. Budget for that.
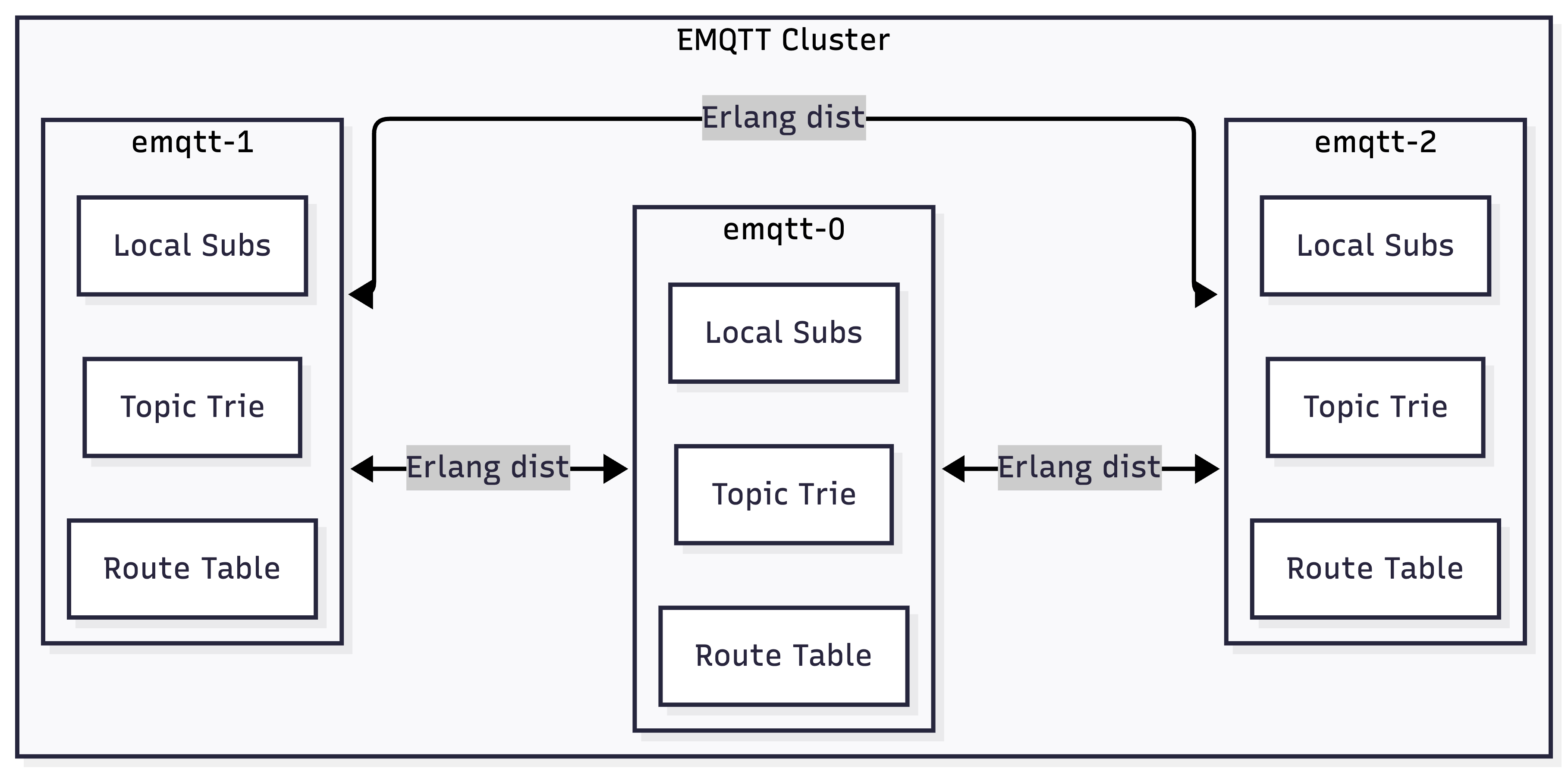
The EMQTT clustering model
EMQTT nodes form a full-mesh cluster using Erlang's native distributed computing (epmd). This is not some application-level clustering bolted on after the fact - it's the same mechanism that powers WhatsApp and Discord's Erlang infrastructure. Each node maintains three data structures:
- A topic trie backed by Mnesia (Erlang's built-in distributed database) for pattern matching on wildcard subscriptions
- A route table mapping topics to nodes that have subscribers
- A local subscription table mapping topics to connected clients on this node
When a client publishes a message, the local node consults the route table, finds which nodes have matching subscribers, forwards the message to those nodes via Erlang distribution, and each receiving node delivers to its local clients. Cross-node message delivery happens in the Erlang VM's native binary format - no serialization overhead, no HTTP calls, no external message broker in the critical path.
The Kubernetes auto-discovery mode queries the K8s API server for pod endpoints matching a headless service:
EMQX_CLUSTER__DISCOVERY=k8s
EMQX_CLUSTER__K8S__APISERVER=https://kubernetes.default.svc
EMQX_CLUSTER__K8S__SERVICE_NAME=emqtt-headless
EMQX_CLUSTER__K8S__ADDRESS_TYPE=dns
EMQX_CLUSTER__K8S__NAMESPACE=messaging
When a new pod starts, it discovers existing cluster members through the headless service DNS, joins the Erlang cluster, syncs the routing table, and starts accepting connections. Scale the StatefulSet from 3 to 5 replicas and new nodes join automatically.
The polyglot reality: four languages, one platform
Before I get into the MQTT topic design, I need to explain why we ended up with four programming languages. This wasn't a grand architectural vision - it was pragmatic engineering driven by what each domain demanded.
Managed C++ for MetaTrader 4 and MetaTrader 5 integrations. There's no choice here. The MT4 Manager API and MT5 Gateway API are native C++ libraries. MetaQuotes provides C++ headers and .lib files, and that's what you work with. We have two distinct services: the MT4 C++ Interface and the MT5 C++ Interface, each wrapping its respective MetaQuotes vendor library. These run as Windows containers on ECS - a separate cluster from our Kubernetes workloads but in the same VPC, sharing RabbitMQ over internal DNS.
Each service has two communication patterns. For outbound data - tick prices and trade execution events - the C++ services hook directly into RabbitMQ, publishing Protobuf-serialized blobs to the market.ticks exchange. Not JSON, not plain text. Protobuf all the way from the MetaTrader callback through the RabbitMQ wire to the consuming Go bridge. The binary payloads keep serialization overhead minimal on the C++ side and the MQTT bridge just forwards the blob as-is to EMQTT - zero deserialization on the hot path.
For inbound commands - create order, cancel order, modify order, set stop loss, take profit - the services expose gRPC interfaces. The API gateway and the Scala copy-trading engine call into these gRPC endpoints synchronously when a trader places an order or a copy signal needs execution. gRPC gives us strongly typed request/response contracts (Protobuf service definitions), proper error codes, and deadline propagation - all things you desperately want when the call is "please open a $50,000 forex position." The MT4 interface translates gRPC calls into Manager API operations, the MT5 interface translates them into Gateway API operations. Same .proto service definition, two implementations. Consumers don't care which MetaTrader version is behind the interface.
These are also the services nobody volunteers to debug.
Scala for social components and Interactive Brokers integration. Our social feed (activity streams, trade sharing, copy-trade signal processing, follower/following graphs) and the Interactive Brokers TWS API integration are written in Scala, running on the JVM with Akka for concurrency. The social data persists to its own dedicated PostgreSQL database - separate from trading data - and gets indexed into Elasticsearch on AWS for fast search, activity feeds, and analytics queries. The IB integration was a natural fit - the TWS API has a solid Java client library, and Scala's functional patterns handle the complex state management of maintaining persistent IB sessions, processing market data callbacks, and managing order lifecycle events. The social feed is essentially an event-sourced activity stream - Scala's pattern matching and Akka Streams made that implementation significantly cleaner than what it would have looked like in Go. The social team came from a Scala/JVM background and they're productive in it. You don't force people to rewrite working code in your preferred language because you read a blog post about monoglot architectures.
Go for the chat system, MQTT bridge, OHLCV pipeline, TradingView integration, and API gateway. Chat is the service I built and the one this blog post is primarily about, but Go runs a lot more than chat here. Go's goroutine model maps perfectly to "one goroutine per connection" for the chat backend, the MQTT bridge service that consumes from RabbitMQ and publishes to EMQTT, and the API gateway that handles REST traffic. The OHLCV Builder - which aggregates raw ticks into candlestick bars across six timeframes - is Go because it's a tight event loop consuming from RabbitMQ at high throughput with minimal allocation. The TradingView Integration API is Go because it's an HTTP server with concurrent SSE streams that maps cleanly to goroutines. Go compiles to a single static binary, produces tiny Docker images from scratch, and starts in milliseconds. The chat service, the MQTT bridge, the OHLCV builder, the TradingView API, the presence service, and the API gateway are all Go.
Python with Celery for scheduled and recurring tasks. Settlement calculations, end-of-day reporting, KYC document processing, email digest compilation, subscription billing, data cleanup jobs - none of these are latency-sensitive and all benefit from Python's rich ecosystem. Celery workers consume tasks from RabbitMQ (same cluster, different vhosts), with Celery Beat scheduling periodic jobs. Using Python for batch processing while Go and Scala handle real-time traffic is a perfectly valid split, and anyone who tells you otherwise has never had to implement XIRR calculations in Go.
Is this architecture "clean" in the way a conference talk would present it? No. Is it honest about how real systems get built when you have teams with different strengths, vendor APIs that dictate your language, and deadlines that don't care about your opinions on monoglot purity? Yes. The services communicate through RabbitMQ and gRPC. They don't care what language the other side is written in.
RabbitMQ as the backbone (and why not Kafka)
I know what you're thinking. "2018, event-driven microservices, financial data - why not Kafka?"
Because RabbitMQ does what we need and we already knew how to operate it. That's the real answer. The more nuanced answer:
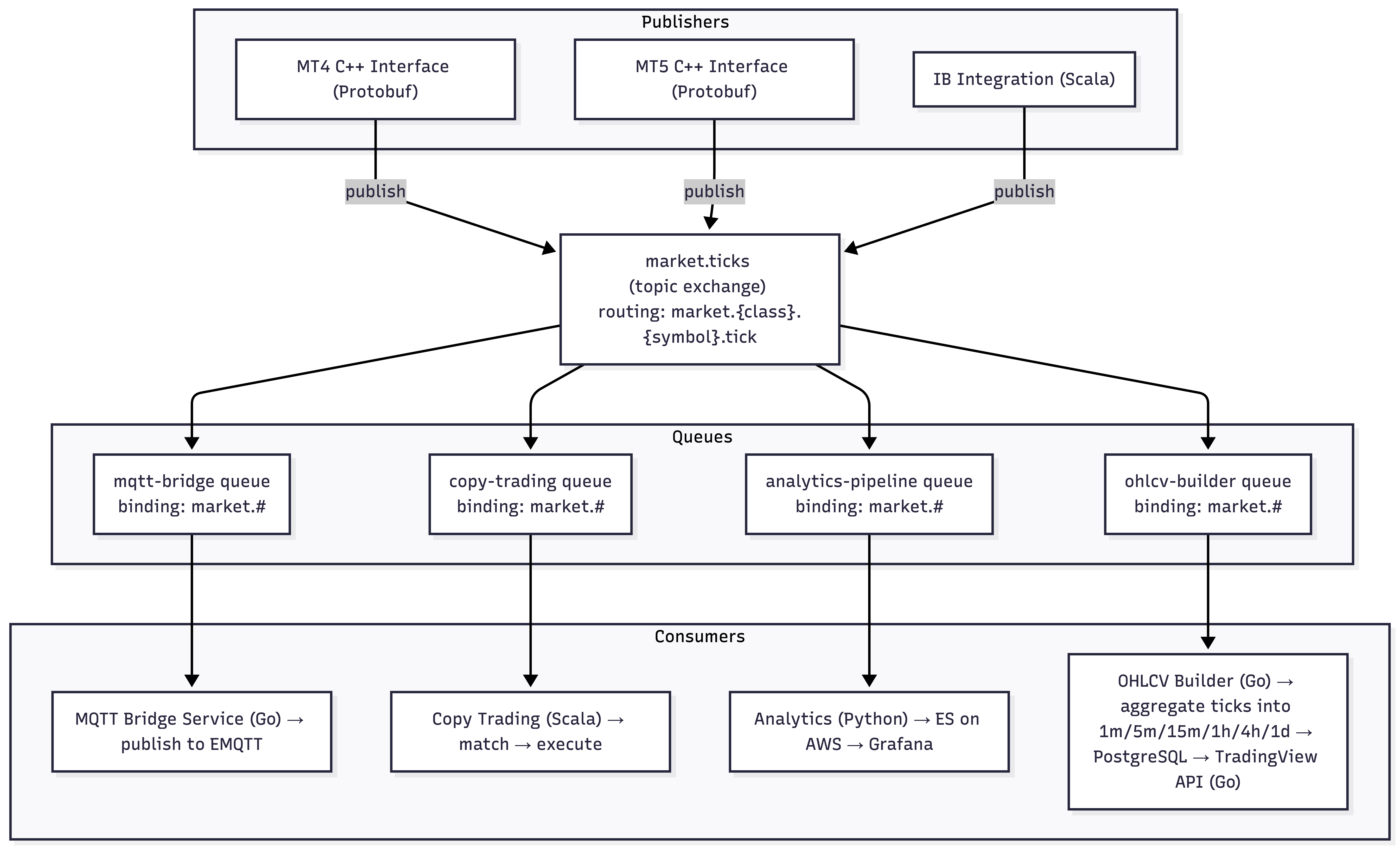
RabbitMQ's exchange-based routing maps naturally to our fan-out patterns. A tick data exchange of type topic lets the MT4 bridge publish to market.forex.EURUSD.tick and have multiple consumers - the MQTT bridge, the copy-trading engine, the analytics pipeline - each with their own queue bound with different routing keys. This is RabbitMQ's core model and it works without ceremony.
For chat, RabbitMQ's acknowledgment model and dead-letter exchanges give us exactly the delivery guarantees we need. A chat message published with persistent: true and consumed with manual ack survives a broker restart and won't be lost if a consumer crashes mid-processing. Failed messages route to a dead-letter exchange for inspection and replay.
We use RabbitMQ vhosts to isolate workloads:
vhost: /trading - tick data, trade events, order routing
vhost: /social - activity feed, copy signals, follower events
vhost: /chat - chat message persistence, notification dispatch
vhost: /celery - Celery task queues (scheduled jobs, reports, KYC)Per-vhost monitoring, permissions, and resource isolation without running multiple RabbitMQ clusters.
The exchange topology for real-time data:
Where Kafka would win: if we needed to replay the entire market data history for a new consumer, or if the log IS the source of truth. We don't. Our sources of truth are PostgreSQL databases - separate instances for trading data and for social/chat data. RabbitMQ is the transport layer, not the storage layer. And the operational overhead of running Kafka with ZooKeeper on K8s in 2018 is significantly higher than RabbitMQ. The best message broker is the one your team can debug at 3 AM.
MQTT topic architecture: making one protocol do two jobs
Financial tick data topics
market/{source}/{instrument}/tickmarket/{source}/{instrument}/depth
market/{source}/{instrument}/ohlcvExamples:
market/mt4/EURUSD/tick → {"b":1.1734,"a":1.1736,"t":1536935412}market/mt5/BTCUSD/tick → {"b":6485.20,"a":6485.80,"t":1536935412}
market/ib/AAPL/tick → {"b":221.50,"a":221.55,"v":1200,"t":1536935412}The {source} segment is critical. EURUSD comes from both MT4 liquidity providers and Interactive Brokers with different spreads and update frequencies. A client on an MT4 account subscribes to market/mt4/EURUSD/tick. A watchlist uses market/+/EURUSD/tick to get all sources. All ticks at QoS 0 - fire and forget.
Retained messages on market/{source}/{instrument}/last give new subscribers the last known price immediately.
The OHLCV Builder also publishes live candle updates to EMQTT:
market/{source}/{instrument}/ohlcv [QoS 0, throttled to 1/sec]market/mt4/EURUSD/ohlcv → {"o":1.1730,"h":1.1742,"l":1.1728,"c":1.1734,"v":42100,"tf":"1m","t":1536935400}These are in-progress candles - the close price and volume update as ticks arrive, throttled to one publish per second to avoid flooding the wire. The TradingView API subscribes to these for real-time chart updates. Completed candles get written to PostgreSQL and don't need MQTT anymore - they're served via REST.
Social chat topics
chat/group/{groupId}/messages [QoS 1]
chat/dm/{sortedUserPair}/messages [QoS 1]
chat/user/{userId}/notifications [QoS 1]
social/feed/{userId}/activity [QoS 0]DM topics use lexicographically sorted user IDs: chat/dm/user123_user456/messages regardless of who initiates. Deterministic, stateless, no lookup needed.
Copy trading via shared subscriptions
$share/copy-workers/copy/+/tradesEMQTT's shared subscription distributes copy signals round-robin across three Scala worker instances. Each signal processed by exactly one worker.
ACL enforcement
EMQTT's HTTP auth plugin calls our Go Auth Service on every CONNECT, SUBSCRIBE, and PUBLISH. JWT in the password field, topic permissions verified against user roles and subscription tiers.
The full service architecture
How a tick reaches the screen
- MT4 C++ Interface receives a price update via the MetaQuotes Manager API callback, serializes it as a Protobuf blob, and publishes directly to RabbitMQ
market.ticksexchange with routing keymarket.mt4.EURUSD.tick. The payload is already Protobuf on the wire - no JSON intermediary. - MQTT Bridge (Go) consumes from its queue bound to
market.#. The Protobuf blob passes through as-is - the bridge doesn't deserialize it, just wraps it in an MQTT PUBLISH and fires it at EMQTT topicmarket/mt4/EURUSD/tickat QoS 0. Zero deserialization on the hot path. Manual ack - only acknowledges the RabbitMQ message after confirming the MQTT publish completed. - EMQTT routes to all subscribed clients via Erlang distribution across the cluster.
- Client decodes Protobuf payload over MQTT-over-WebSocket and updates UI.
End-to-end: 40-80ms. The IB path adds 10-15ms from the TWS callback model.
How ticks become OHLCV candles and power TradingView
The same market.ticks exchange feeds a fourth consumer: the OHLCV Builder Service (Go). This is one of those services that sounds simple on a whiteboard and turns into a surprisingly nuanced state machine in production.
The OHLCV Builder has its own RabbitMQ queue bound to market.# on the /trading vhost. It consumes every tick from every source and aggregates them into candlestick bars across multiple timeframes: 1-minute, 5-minute, 15-minute, 1-hour, 4-hour, and 1-day. Each instrument/source/timeframe combination maintains an in-memory candle that tracks the open price (first tick of the window), running high and low, the latest close, and accumulated volume. When the time window expires, the completed candle gets flushed to PostgreSQL (the trading database) and the in-memory state resets for the next window.
The tricky parts: handling market gaps (weekends, holidays - the candle window doesn't close on schedule if no ticks arrive), timezone-aware daily candles (forex daily close is 5 PM EST, not midnight UTC), and ensuring that a service restart mid-window doesn't produce a candle with incorrect open/high/low values. We solve the restart problem by writing in-progress candle state to Redis on every tick (cheap - it's just a few fields per active instrument/timeframe pair) and recovering from Redis on startup. If the service was down for less than one candle window, the recovery is seamless. If it was down longer, we backfill from the raw tick archive.
The completed OHLCV data serves two consumers:
The TradingView Integration API - a separate Go service that serves as the backend for TradingView's Charting Library (v1.12). TradingView doesn't consume a REST API directly - it expects a JavaScript Datafeed object passed to the Widget constructor on the frontend, implementing a set of callback-driven methods. Our frontend Datafeed implementation calls our Go backend API, which does the actual data fetching. The core methods we implement:
// Frontend: datafeed.js - implements TradingView JS API (v1.12)
{
onReady: (callback) => {
// Must be async - setTimeout required
setTimeout(() => callback({
supported_resolutions: ['1', '5', '15', '60', '240', 'D'],
supports_marks: false,
supports_search: true,
}), 0);
},
resolveSymbol: (symbolName, onResolvedCallback, onErrorCallback) => {
// GET /api/symbols?symbol=EURUSD → symbolInfo object
api.get(`/symbols?symbol=${symbolName}`).then(info => onResolvedCallback(info));
},
getBars: (symbolInfo, resolution, from, to, onHistoryCallback, onErrorCallback, firstDataRequest) => {
// GET /api/history?symbol=EURUSD&resolution=5&from=1536000000&to=1536935412
// Note: 'from' and 'to' are Unix seconds, but returned bar.time must be milliseconds
api.get(`/history?symbol=${symbolInfo.ticker}&resolution=${resolution}&from=${from}&to=${to}`)
.then(bars => onHistoryCallback(bars, { noData: bars.length === 0 }));
},
subscribeBars: (symbolInfo, resolution, onRealtimeCallback, subscribeUID, onResetCacheNeededCallback) => {
// Connect to our MQTT-over-WebSocket and push new bars via callback
subscribeToMQTT(symbolInfo, resolution, onRealtimeCallback);
},
unsubscribeBars: (subscriberUID) => {
unsubscribeFromMQTT(subscriberUID);
},
}The getBars method is the workhorse - TradingView calls it repeatedly, paginating backward through history. Our Go backend queries PostgreSQL for completed candles using range queries on a (source, instrument, timeframe, timestamp) composite index. For the current incomplete candle, it reads in-progress state from Redis. Timestamps go out in seconds (what TradingView sends as from/to) and come back with time in milliseconds (what TradingView expects in bar objects) - getting this conversion wrong is a rite of passage that every TradingView integration goes through.
The subscribeBars callback is where MQTT comes back into the picture. Instead of TradingView's default UDF polling approach (which hits an HTTP endpoint every 10 seconds - completely inadequate for a live trading platform), our frontend Datafeed connects directly to EMQTT over WebSocket and subscribes to market/{source}/{instrument}/ohlcv. The OHLCV Builder publishes in-progress candle updates at a throttled rate (once per second rather than on every tick). When a new bar arrives over MQTT, we call onRealtimeCallback with the updated {time, open, high, low, close, volume} object and TradingView updates the chart in real-time. No polling, no SSE, just MQTT pushing directly into the charting library's callback.
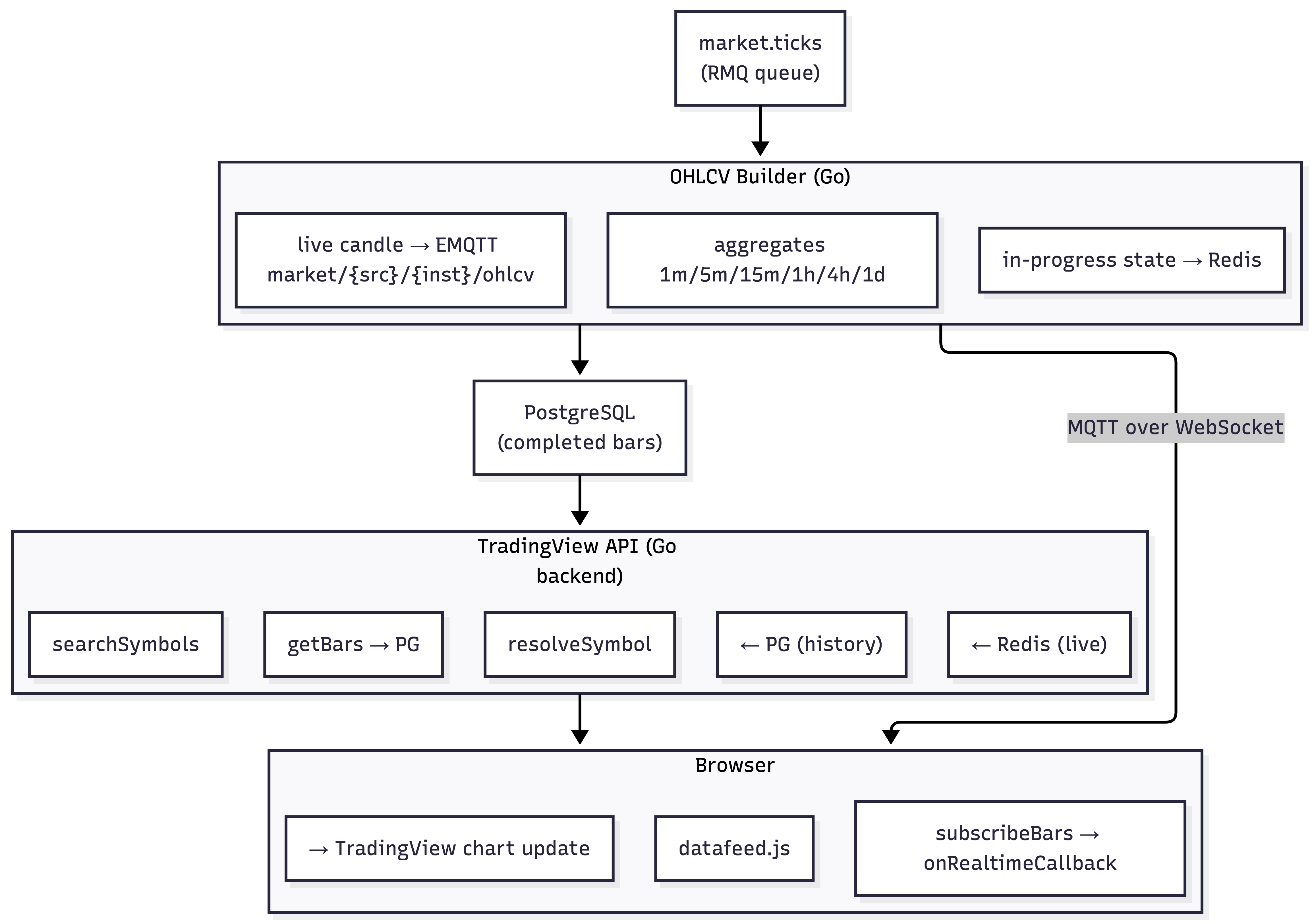
The TradingView integration is one of the highest-value features relative to its implementation cost. TradingView's charting library (we're on v1.12) is the standard that retail traders expect - nobody wants to build a custom charting solution from scratch, and nobody wants to look at a platform that doesn't have proper candlestick charts with drawing tools and indicators. The JS API Datafeed interface is well-documented (if you can get access to the private GitHub repo where the library and wiki live), and the real complexity is in the OHLCV Builder's aggregation logic rather than in the API layer itself. The getBars seven-parameter signature is slightly unwieldy but it works. The library ships with a UDF adapter that can talk to a REST server with predefined endpoints (/config, /history, /symbols), but it uses HTTP polling for real-time updates - 10-second polling intervals are a non-starter for a live trading platform. The JS API with direct MQTT WebSocket streaming is the right approach.
One operational detail worth noting: we run the OHLCV Builder as a single-replica Deployment with a hot standby (a second replica consuming from the same queue but held behind a leader election lock in Redis). OHLCV aggregation is inherently stateful - two instances independently aggregating the same tick stream would produce different candles depending on message distribution. The standby takes over within seconds if the primary dies, recovers in-progress state from Redis, and resumes aggregation. We considered running this as a StatefulSet but the recovery-from-Redis pattern is simpler and avoids the EBS AZ-binding problem entirely.
How a chat message flows
- Client publishes to
chat/group/crypto-signals/messagesat QoS 1 with UUID. - EMQTT delivers to all group subscribers (fan-out on write).
- Chat Service (Go) on shared subscription
$share/chat-workers/chat/#persists to a dedicated PostgreSQL database for chat and social data (separate from the trading databases), and indexes to Elasticsearch on AWS for fast full-text search and analytics queries. Offline recipients →chat.eventsexchange on RabbitMQ. - Notification Service (Go) consumes and pushes via FCM/APNS.
Scheduled tasks with Celery
app = Celery('platform',
broker='amqp://celery:[email protected]:5672/celery',
backend='redis://redis.platform.svc:6379/0')
app.conf.beat_schedule = {
'settlement-daily': {
'task': 'tasks.settlement.run_daily_settlement',
'schedule': crontab(hour=22, minute=0),
},
'pnl-report-daily': {
'task': 'tasks.reports.generate_daily_pnl',
'schedule': crontab(hour=0, minute=30),
},
'stale-session-cleanup': {
'task': 'tasks.cleanup.purge_stale_sessions',
'schedule': 900.0,
},
}
app.conf.task_routes = {
'tasks.settlement.*': {'queue': 'settlement'},
'tasks.reports.*': {'queue': 'reports'},
'tasks.kyc.*': {'queue': 'kyc'},
}Beat as single-replica Deployment (Redis lock for leader election). Workers as Deployment with HPA on CPU. Separate queues for independent scaling.
Running Kubernetes on AWS (before EKS existed)
EKS went GA June 2018. We started late 2017. Self-managed K8s on EC2 was the only option.
kops
kops create cluster \
--name=prod.k8s.example.com \
--state=s3://kops-state-prod \
--zones=eu-west-1a,eu-west-1b,eu-west-1c \
--master-zones=eu-west-1a,eu-west-1b,eu-west-1c \
--master-count=3 \
--master-size=m5.xlarge \
--node-count=6 \
--node-size=m5.2xlarge \
--networking=calico \
--topology=private \
--bastionGood at creating clusters. Less good at everything after. Upgrading across K8s minor versions is white-knuckle. CVE-2018-1002105 last month forced a multi-version upgrade in one day. We generate Terraform from kops for PR-reviewed infrastructure changes.
Calico over Flannel
Flannel doesn't support NetworkPolicies. CySEC-regulated platform needs network-level namespace isolation. Calico: BGP routing, no overlay overhead, full NetworkPolicy support. More complex to debug, correct for production.
The EBS AZ trap
EBS volumes are AZ-bound. StatefulSet pods with PVCs can't reschedule across AZs. Affects both EMQTT and RabbitMQ. Solutions: per-AZ StatefulSets, soft anti-affinity with mirrored queues, volumeBindingMode: WaitForFirstConsumer.
NLB for MQTT, kiam for IAM
NLB for Layer 4 TCP passthrough. TLS termination at Nginx. kiam for pod-level IAM (migrated from kube2iam after race condition issues).
EMQTT StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: emqtt
namespace: messaging
spec:
serviceName: emqtt-headless
replicas: 3
podManagementPolicy: Parallel
template:
spec:
containers:
- name: emqtt
image: emqx/emqx:v2.3.11
ports:
- containerPort: 1883
name: mqtt
- containerPort: 8083
name: mqtt-ws
- containerPort: 18083
name: dashboard
- containerPort: 4369
name: epmd
env:
- name: EMQX_CLUSTER__DISCOVERY
value: "k8s"
- name: EMQX_CLUSTER__K8S__SERVICE_NAME
value: "emqtt-headless"
- name: EMQX_CLUSTER__K8S__ADDRESS_TYPE
value: "dns"
- name: EMQX_CLUSTER__K8S__NAMESPACE
value: "messaging"
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
readinessProbe:
httpGet:
path: /status
port: 18083
initialDelaySeconds: 30
livenessProbe:
httpGet:
path: /status
port: 18083
initialDelaySeconds: 60
failureThreshold: 5Production incident lessons:
podManagementPolicy: Parallel - default OrderedReady starts pods sequentially. No ordering dependency for a broker cluster.
Liveness initialDelaySeconds: 60, failureThreshold: 5 - Erlang VMs take time to start and sync Mnesia. First deploy with defaults (10s, 3 failures): infinite restart loop for 20 minutes.
Port 4369 (epmd) - without this in the headless service, Erlang distribution can't form the cluster. First deployment: three independent brokers, none forwarding messages. Embarrassingly long to diagnose.
OS tuning
fs.file-max = 2097152
net.core.somaxconn = 32768
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_local_port_range = 1024 65535
We run 30K-50K connections per node on m5.2xlarge.
The WebSocket gateway
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
upstream emqtt_websocket {
server emqtt-0.emqtt-headless.messaging.svc.cluster.local:8083;
server emqtt-1.emqtt-headless.messaging.svc.cluster.local:8083;
server emqtt-2.emqtt-headless.messaging.svc.cluster.local:8083;
}
server {
listen 443 ssl http2;
server_name mqtt.platform.example.com;
location /mqtt {
proxy_pass http://emqtt_websocket;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_read_timeout 600s;
proxy_send_timeout 600s;
proxy_buffering off;
}
}proxy_read_timeout 600s - Nginx default 60s races against MQTT keepalive 60s. Set to 10x and forget about it. proxy_buffering off prevents frame buffering.
Client-side MQTT
const client = mqtt.connect('wss://mqtt.platform.example.com/mqtt', {
clientId: `${userId}_web_${crypto.randomBytes(4).toString('hex')}`,
username: userId,
password: jwtToken,
clean: true,
keepalive: 60,
reconnectPeriod: 0,
will: {
topic: `presence/${userId}`,
payload: JSON.stringify({ status: 'offline', ts: Date.now() }),
qos: 1, retain: true
}
});
// Exponential backoff with jitter - not optional
let reconnectAttempt = 0;
client.on('close', () => {
reconnectAttempt++;
const delay = Math.min(30000,
1000 * Math.pow(2, reconnectAttempt) + Math.random() * 1000
);
setTimeout(() => client.reconnect(), delay);
});
client.on('connect', () => {
reconnectAttempt = 0;
client.publish(`presence/${userId}`,
JSON.stringify({ status: 'online', ts: Date.now() }),
{ qos: 1, retain: true });
});
The jitter is not optional. Slack lost 1.6M connections during a deploy and recovery took 2+ hours from synchronized reconnects.
Deployment pipeline
Go - multi-stage, scratch base, ~8MB:
FROM golang:1.10-alpine AS builder
COPY . .
RUN CGO_ENABLED=0 go build -ldflags="-w -s" -o /go/bin/chat-service ./cmd/chat-service
FROM scratch
COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/
COPY --from=builder /go/bin/chat-service /chat-service
ENTRYPOINT ["/chat-service"]Scala - sbt assembly, JRE base, ~250MB:
FROM hseeberger/scala-sbt:8u181_2.12.6_1.2.1 AS builder
RUN sbt assembly
FROM openjdk:8-jre-alpine
COPY --from=builder /app/target/scala-2.12/social-feed-assembly.jar /app.jar
ENTRYPOINT ["java", "-Xmx2g", "-jar", "/app.jar"]Python - pip, slim base, ~120MB:
FROM python:3.6-slim
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["celery", "-A", "celery_app", "worker", "-Q", "default,settlement,reports"]C++ MT4/MT5 interfaces - Windows container builds, run on ECS with Windows container instances. Two separate ECS services: mt4-interface and mt5-interface. AWS added Windows container support to ECS in late 2017 and we were early adopters. The MetaQuotes APIs require a Windows runtime, so Linux containers are off the table. The Dockerfile uses a microsoft/windowsservercore base, copies in the MetaQuotes SDK and our managed C++ binaries. Each container hooks directly into RabbitMQ over AMQP for outbound tick data and trade events (all Protobuf-serialized), and exposes gRPC endpoints for inbound order management (create, cancel, modify, stop loss, take profit). ECS handles scheduling across a small pool of Windows EC2 instances. These don't live in our Kubernetes cluster - ECS and K8s coexist in the same VPC, sharing RabbitMQ and gRPC connectivity over internal DNS. Running Windows containers on K8s in 2018 is technically possible (1.9 added Windows node support in beta) but the ecosystem is nowhere near production-ready. ECS was the pragmatic choice.
Jenkins for all pipelines. Push to master: test → Docker build → ECR push → Helm upgrade to staging → manual promotion to production.
Monitoring
Prometheus Operator with custom exporters for EMQTT ($SYS/#) and RabbitMQ (rabbitmq_exporter). Grafana dashboards:
- EMQTT: connection count per node, pub/sub rates, QoS 1 retries, Erlang VM health
- RabbitMQ: queue depths per vhost (non-zero on mqtt-bridge = stale prices = P1), message rates, consumer count, memory alarms
- Celery: task success/failure rates, execution percentiles, queue lengths per category
The ratio between RabbitMQ publish rate on market.ticks and EMQTT delivery rate is the end-to-end health metric.
EFK for logging - structured JSON, trace IDs propagating from C++ interfaces through RabbitMQ headers (embedded in Protobuf envelope) to Go bridge to EMQTT to client.
What we got wrong
Erlang operational complexity. First cluster split-brain required understanding Mnesia merge conflicts. Two people now read Erlang source.
Flat topic hierarchy. Topics like tick-EURUSD with no hierarchy meant no wildcard support. Redesign required synchronized changes across C++ interfaces, Scala services, Go bridge, client library, ACL rules, and monitoring.
Connection draining during rolling updates. 15K clients reconnecting simultaneously overwhelmed remaining nodes. Fixed with longer termination grace periods, preStop hooks, staggered updates.
Four languages = four of everything. Four pipelines, debuggers, dependency managers. RabbitMQ client bug? Fix in streadway/amqp (Go), com.rabbitmq:amqp-client (Scala), pika (Python), and rabbitmq-c (C++). Only pay the polyglot tax when the domain demands it.
RabbitMQ queue alerts need per-queue tuning. Depth 1K on the tick bridge queue = stale prices (P1). Depth 1K on Celery reports queue = slow EOD reports (Tuesday). First config treated all queues the same.
Should have invested in distributed tracing from day one. Tracing across four languages and two message brokers by grepping logs is unsustainable. Integrating Jaeger now.
The lessons
MQTT is legitimate for more than IoT. We power a regulated trading platform with MetaTrader and IB data plus social chat on the same broker cluster.
RabbitMQ is still excellent. Not as fashionable as Kafka. Also doesn't require ZooKeeper, is operationally simpler, has better routing for our patterns. The best broker is the one your team can debug at 3 AM.
Polyglot works when the domain demands it. C++ for MetaQuotes. Scala for JVM trading APIs. Go for connections. Python for batch. Concrete justifications, not preferences.
QoS is your delivery guarantee type system. QoS 0 for ticks. QoS 1 for chat. QoS 2 for nothing.
Self-managed K8s is doable. EKS will be better. Migration planned Q1 2019.
The boring technology principle applies double. PostgreSQL (separate databases for trading and social/chat), Redis, RabbitMQ, Elasticsearch on AWS. When your business logic is already complex, your infrastructure should be the simplest thing that works.
If you're facing similar challenges, let's talk.
Bring the current architecture context and delivery constraints, and we can map out a focused next step.
Book a Discovery CallNewsletter
Stay connected
Not ready for a call? Get the next post directly.