BLOG POST
gRPC + Go + Kafka + Cassandra: A Stack for Low-Latency Financial Data
I've spent the better part of two years building and operating financial data infrastructure on top of gRPC, Go, Kafka, and Cassandra. Not toy projects - production systems processing market data, trade executions, and risk calculations where a 50ms latency spike at 2:31 PM on a Tuesday means someone's algo ate a bad fill and you're writing a post-mortem instead of going home.
This post is the write-up I wish existed when I started. Not the "hello world gRPC tutorial" kind. The kind where I tell you what actually happens when you push 400K quote updates per second through this stack, what happens when a Kafka consumer group rebalances during a market open, what Cassandra does to your disk at 3 AM during compaction, and why your gRPC load balancer is silently routing everything to one pod.
If you're evaluating this stack for financial workloads - or any workload where "low-latency" isn't a marketing term but a contractual SLA - read on. I'll cover the architecture end to end: protobuf as the universal serialization format (on the wire and on Kafka topics), Kafka as the central event backbone, a dedicated gRPC writer service for Cassandra persistence, Cassandra compaction strategies for tick data, and deploying the whole thing on Kubernetes with Strimzi without losing your mind.
Why This Stack, Why Now
The traditional enterprise approach to financial data infrastructure is some variation of Java/Spring Boot + REST/JSON + PostgreSQL (or Oracle, if someone hates the budget). These stacks deliver 10–50ms p50 latency and 50–200ms at p99. That's fine for a web app. It's not fine when you're ingesting thousands of market data ticks per second from multiple exchanges and your downstream consumers need that data now, not "whenever the JSON serializer and the connection pool and the ORM feel like it."
On the other extreme, you have the C++/FIX-on-bare-metal crowd achieving ~15µs round-trips with kernel bypass, FPGA acceleration, and colocation. That's a different universe - one where you're spending 3–10x more engineering effort, hiring from a tiny talent pool, and your deployment process involves physically shipping servers to data centers in New Jersey.
The gRPC + Go + Kafka + Cassandra stack sits in the middle, and that middle is where 90% of actual financial workloads live. We're talking:
- Trade capture and lifecycle management
- Market data normalization and distribution
- Position and risk calculation
- Post-trade processing and settlement
- Regulatory reporting pipelines
- Portfolio analytics
For these workloads, this stack delivers 2–8ms p50 latency and 10–25ms at p99 end-to-end (feed ingestion through Kafka to Cassandra persistence). That's a 5–10x improvement over the Java/REST/RDBMS baseline, with dramatically better write throughput, horizontal scalability, and - critically - the ability to replay the entire event stream when something goes wrong. And you can hire Go developers. Try hiring someone who can write lock-free C++ for a matching engine - I'll wait.
The production evidence is compelling. Monzo runs 1,500+ Go microservices on Cassandra and Kubernetes - that's an entire bank. American Express processes payments at 140,000 requests per second in Go after their "Language Showdown" comparing C++, Go, Java, and Node.js. Bloomberg operates 1,700+ Cassandra nodes handling 20 billion daily requests for their fixed income index platform. LinkedIn processes 7+ trillion messages per day through Kafka. This isn't theoretical. These are production numbers from organizations that would notice if things broke.
The Architecture at a Glance
Before diving into each component, here's the high-level data flow. Every message on every transport layer is protobuf. No JSON anywhere in the hot path.
Key design decision: Kafka sits between the feed handlers and everything else. The feed handlers' only job is to connect to exchanges, normalize the raw protocol (FIX, WebSocket, proprietary binary) into protobuf messages, and produce to Kafka. That's it. They don't write to Cassandra. They don't fan out to consumers. They don't do business logic. They produce protobuf blobs to Kafka topics and nothing else.
The dedicated Cassandra writer is a separate Go service that consumes from Kafka and writes to Cassandra via a gocql session. This separation is deliberate and I'll explain why in the Kafka section.
All other consumers - risk engine, analytics, client-facing gRPC streaming API - consume from the same Kafka topics independently. Each consumer group reads at its own pace, with its own offset management, without affecting anyone else.
gRPC in Go: Fast Binary RPC With Streaming
The Basics That Matter
The google.golang.org/grpc library is mature at this point - we're on versions v1.27/v1.28, shipping on a roughly six-week cadence. It supports all four RPC patterns:
| Pattern | Financial Use Case | When To Use |
|---|---|---|
| Unary | Trade submission, quote lookup, position query | Single request, single response |
| Server streaming | Market data feed, price subscriptions | Server pushes continuous updates |
| Client streaming | Batch order submission, bulk trade upload | Client sends many, server responds once |
| Bidirectional streaming | Interactive order book, live trading session | Both sides send continuously |
In our architecture, gRPC serves two distinct roles. First, the client-facing API layer: external clients subscribe to market data via gRPC server streaming, submit orders via unary RPCs, and get execution reports via bidirectional streaming. Second, the Cassandra writer service exposes a gRPC interface for internal services that need synchronous write confirmation (the writer itself consumes from Kafka for the bulk ingestion path, but other services can call it directly for low-volume writes that need immediate acknowledgment).
Here's what the financial services proto definition looks like in practice:
syntax = "proto3";
package financial.marketdata.v1;
import "google/protobuf/timestamp.proto";
service MarketDataService {
// Continuous price feed - server streaming
// Backed by a Kafka consumer under the hood
rpc StreamPrices(PriceSubscription) returns (stream PriceUpdate);
// Single quote lookup - unary, reads from Cassandra
rpc GetQuote(QuoteRequest) returns (QuoteResponse);
// Batch order submission - client streaming
rpc SubmitOrders(stream OrderRequest) returns (OrderBatchSummary);
// Interactive trading session - bidirectional
rpc LiveTrading(stream TradingMessage) returns (stream TradingMessage);
}
// Dedicated Cassandra writer - internal only
service TickWriterService {
// Synchronous write for low-volume cases that need immediate ack
rpc WriteTick(PriceUpdate) returns (WriteAck);
rpc WriteBatch(TickBatch) returns (WriteAck);
}
message WriteAck {
bool success = 1;
string error = 2;
int64 write_latency_us = 3; // self-reported write time in microseconds
}
message TickBatch {
repeated PriceUpdate ticks = 1;
}
// ═══════════════════════════════════════════════════════════════
// PRICE DATA
// These same messages are used on:
// 1. gRPC wire (client ↔ server)
// 2. Kafka topics (serialized as raw protobuf bytes)
// 3. Internal service communication
// One schema, everywhere. No translation layers.
// ═══════════════════════════════════════════════════════════════
// Price representation using fixed-point to avoid IEEE 754 issues.
// price_micros = actual_price * 1_000_000
// e.g., $152.37 → 152370000
message PriceUpdate {
string exchange = 1;
string symbol = 2;
int64 bid_micros = 3; // fixed-point, 6 decimal places
int64 ask_micros = 4;
int64 last_micros = 5;
int64 volume = 6;
google.protobuf.Timestamp event_time = 7; // exchange timestamp
google.protobuf.Timestamp received_time = 8; // our ingestion timestamp
string feed_handler_id = 9; // which feed handler produced this
}
message PriceSubscription {
repeated string symbols = 1;
string exchange = 2;
int32 throttle_ms = 3; // conflation window
}
message QuoteRequest {
string symbol = 1;
string exchange = 2;
}
message QuoteResponse {
PriceUpdate latest = 1;
int64 day_high_micros = 2;
int64 day_low_micros = 3;
int64 open_micros = 4;
int64 prev_close_micros = 5;
}
message OrderRequest {
string order_id = 1;
string symbol = 2;
string side = 3; // BUY, SELL
int64 quantity_micros = 4;
int64 limit_price_micros = 5; // 0 for market orders
string order_type = 6; // LIMIT, MARKET, STOP
google.protobuf.Timestamp client_timestamp = 7;
}
message OrderBatchSummary {
int32 accepted = 1;
int32 rejected = 2;
repeated string rejection_reasons = 3;
}
message TradingMessage {
oneof payload {
OrderRequest new_order = 1;
OrderCancelRequest cancel = 2;
ExecutionReport execution = 3;
OrderStatusUpdate status = 4;
}
}
message OrderCancelRequest {
string order_id = 1;
string reason = 2;
}
message ExecutionReport {
string execution_id = 1;
string order_id = 2;
int64 fill_price_micros = 3;
int64 fill_quantity_micros = 4;
google.protobuf.Timestamp execution_time = 5;
}
message OrderStatusUpdate {
string order_id = 1;
string status = 2; // NEW, PARTIAL, FILLED, CANCELLED, REJECTED
int64 remaining_quantity_micros = 3;
}A note on the decimal representation problem, because this trips people up. Protobuf has no native decimal type. IEEE 754 floats are unacceptable for financial calculations - 0.1 + 0.2 != 0.3 is not a rounding error you can hand-wave in a system that moves money. The two viable approaches are:
- Fixed-point integers (what I use above): multiply by a known factor (micros = 10^6, basis points = 10^4). Wire-efficient, fast arithmetic, zero ambiguity. The server and client agree on the scale factor, and you do integer math everywhere.
- Google Money-style
units + nanos: asint64 unitsfield for the whole part and anint32 nanosfield (0–999,999,999) for fractional. Nine decimal places of precision. More flexible but slightly more complex to handle in application code.
I've used both. Fixed-point micros is simpler and faster for the common case where you know your precision requirements up front (which you almost always do in finance - currency pairs have defined tick sizes).
The Serialization Advantage
This is where the "why not just use REST" conversation ends. And it's also why we use protobuf on Kafka topics instead of Avro or JSON. Here are real numbers from Go benchmarks:
| Operation | Protobuf | JSON | Improvement |
|---|---|---|---|
| Marshal | ~557–875 ns/op | ~1,531–3,250 ns/op | 3–4x faster |
| Unmarshal | ~599–650 ns/op | ~4,570–4,850 ns/op | 7x faster |
| Allocations per marshal | 4 | 24 | 6x fewer |
| Wire size (typical Order) | ~190 bytes | ~500 bytes | 2.6x smaller |
Those allocation numbers matter more than the raw speed. Every allocation is future GC work. When you're processing 100K messages/second - which is what the Kafka consumers are doing - the difference between 4 and 24 allocations per message is the difference between smooth sailing and GC-induced latency spikes. This applies on the Kafka produce side, the Kafka consume side, the gRPC transport, and the Cassandra write path. Same message format everywhere means you marshal once at the edge (feed handler) and just pass the bytes through Kafka. The consumer deserializes directly into the same Go struct that gRPC and gocql understand. No translation layers, no schema registries, no impedance mismatch.
Under realistic load - 500 concurrent client threads with large payloads - gRPC delivers roughly 10x the throughput of REST, and p99 latency is ~11x lower. These aren't synthetic microbenchmarks; they track with what I've seen in production.
The go-trader project on GitHub (a full financial exchange simulator using gRPC) demonstrates 410,000+ quote updates per second with average round-trip time of ~605 microseconds and p99 of ~2.4 milliseconds. That's the gRPC transport layer alone, without Kafka or database writes. It gives you a ceiling to work toward.
Production Middleware Stack
The go-grpc-middleware package (currently at 3,000+ GitHub stars) is essential. It provides interceptor chaining that lets you compose cross-cutting concerns without touching service logic. Here's the server-side interceptor stack I run in production:
import (
grpc_middleware "github.com/grpc-ecosystem/go-grpc-middleware"
grpc_auth "github.com/grpc-ecosystem/go-grpc-middleware/auth"
grpc_zap "github.com/grpc-ecosystem/go-grpc-middleware/logging/zap"
grpc_recovery "github.com/grpc-ecosystem/go-grpc-middleware/recovery"
grpc_prometheus "github.com/grpc-ecosystem/go-grpc-prometheus"
"go.uber.org/zap"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
"google.golang.org/grpc/keepalive"
"time"
)
func NewFinancialGRPCServer(
logger *zap.Logger,
tlsCreds credentials.TransportCredentials,
authFunc grpc_auth.AuthFunc,
) *grpc.Server {
recoveryOpts := []grpc_recovery.Option{
grpc_recovery.WithRecoveryHandler(func(p interface{}) error {
logger.Error("panic recovered in gRPC handler",
zap.Any("panic", p),
zap.Stack("stack"),
)
return grpc.Errorf(codes.Internal, "internal error")
}),
}
server := grpc.NewServer(
grpc.Creds(tlsCreds),
grpc.KeepaliveParams(keepalive.ServerParameters{
MaxConnectionIdle: 5 * time.Minute,
MaxConnectionAge: 30 * time.Minute, // force reconnect for LB
MaxConnectionAgeGrace: 10 * time.Second,
Time: 1 * time.Minute,
Timeout: 20 * time.Second,
}),
grpc.KeepaliveEnforcementPolicy(keepalive.EnforcementPolicy{
MinTime: 30 * time.Second,
PermitWithoutStream: true,
}),
grpc.MaxRecvMsgSize(16 * 1024 * 1024), // 16MB
grpc.MaxSendMsgSize(16 * 1024 * 1024),
grpc.UnaryInterceptor(grpc_middleware.ChainUnaryServer(
grpc_recovery.UnaryServerInterceptor(recoveryOpts...),
grpc_prometheus.UnaryServerInterceptor,
grpc_zap.UnaryServerInterceptor(logger),
grpc_auth.UnaryServerInterceptor(authFunc),
)),
grpc.StreamInterceptor(grpc_middleware.ChainStreamServer(
grpc_recovery.StreamServerInterceptor(recoveryOpts...),
grpc_prometheus.StreamServerInterceptor,
grpc_zap.StreamServerInterceptor(logger),
grpc_auth.StreamServerInterceptor(authFunc),
)),
)
grpc_prometheus.EnableHandlingTimeHistogram(
grpc_prometheus.WithHistogramBuckets(
[]float64{.001, .005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5},
),
)
return server
}MaxConnectionAge is critical. Set it to something like 30 minutes. This forces clients to periodically reconnect, which triggers DNS re-resolution and redistributes connections across backends. Without this, if you scale up your service from 3 to 6 pods, the existing connections stay pinned to the original 3. I learned this the hard way when a Kubernetes HPA event scaled us to 12 replicas and 80% of traffic was still hitting 4 of them.
mTLS is non-negotiable. Every financial services deployment I've worked on requires mutual TLS:
func loadTLSCredentials() (credentials.TransportCredentials, error) {
serverCert, err := tls.LoadX509KeyPair("server-cert.pem", "server-key.pem")
if err != nil {
return nil, fmt.Errorf("loading server cert: %w", err)
}
caCert, err := ioutil.ReadFile("ca-cert.pem")
if err != nil {
return nil, fmt.Errorf("reading CA cert: %w", err)
}
certPool := x509.NewCertPool()
certPool.AppendCertsFromPEM(caCert)
config := &tls.Config{
Certificates: []tls.Certificate{serverCert},
ClientAuth: tls.RequireAndVerifyClientCert,
ClientCAs: certPool,
MinVersion: tls.VersionTLS12,
}
return credentials.NewTLS(config), nil
}Go 1.12 introduced TLS 1.3 as opt-in, and Go 1.13 (shipped September 2019) made it the default. Free latency reduction for the cost of a version bump.
Deadline Propagation and Retries
gRPC's deadline propagation through Go's context.Context prevents subtle, expensive failures. When a client sets a 5-second deadline, that deadline automatically cascades through every downstream gRPC call. If your order validation service calls the risk service which calls the position service, and the whole chain is gRPC, a timeout at any point correctly propagates back as DEADLINE_EXCEEDED without you writing any timeout-forwarding logic.
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
resp, err := orderClient.SubmitOrder(ctx, &pb.OrderRequest{...})
if err != nil {
st, _ := status.FromError(err)
if st.Code() == codes.DeadlineExceeded {
log.Warn("order submission timed out", zap.String("order_id", req.OrderId))
}
}For retries, the gRPC service config supports automatic retry policies with exponential backoff:
serviceConfig := `{
"methodConfig": [{
"name": [{"service": "financial.marketdata.v1.MarketDataService"}],
"waitForReady": true,
"retryPolicy": {
"maxAttempts": 4,
"initialBackoff": "0.1s",
"maxBackoff": "1s",
"backoffMultiplier": 2,
"retryableStatusCodes": ["UNAVAILABLE", "RESOURCE_EXHAUSTED"]
}
}]
}`
conn, err := grpc.Dial(target,
grpc.WithDefaultServiceConfig(serviceConfig),
)Important: never retry non-idempotent operations like order submissions without an idempotency key. UNAVAILABLE is safe to retry (the server didn't process the request). INTERNAL is not (the server might have processed it and then crashed before responding).
The Load Balancing Problem
This is the single biggest operational headache with gRPC, and I want to be explicit about it because most tutorials skip this entirely.
gRPC uses HTTP/2 long-lived connections. HTTP/2 multiplexes many streams (individual RPCs) over a single TCP connection. Traditional L4 load balancers - including the default kube-proxy in Kubernetes - balance connections, not requests. Once a gRPC client establishes its single HTTP/2 connection to a backend pod, every subsequent RPC travels to that same pod. If you have 10 client instances and 10 server pods, you might end up with all 10 clients connected to 3 servers. I've seen this in production. It's infuriating.
Three solutions:
1. Client-side load balancing with round_robin:
conn, err := grpc.Dial(
"dns:///my-service.default.svc.cluster.local:50051",
grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy":"round_robin"}`),
grpc.WithInsecure(),
)Requires a Kubernetes headless service (clusterIP: None) so DNS returns multiple A records. Combine with MaxConnectionAge on the server to force periodic reconnection.
2. Envoy proxy as L7 load balancer:
Envoy (CNCF graduated) terminates the client's HTTP/2 connection and distributes individual gRPC requests across backends. Adds ~0.5–1ms but gives you proper per-request load distribution, circuit breaking, and observability. NGINX only added gRPC support in March 2018 and it's still not as battle-tested for this use case.
3. Service mesh (Istio/Linkerd):
Both inject proxies as sidecars. gRPC load balancing "for free" at the cost of sidecar overhead. Linkerd 2.x is significantly lighter than Istio for this use case.
Kafka as the Event Backbone
This is the part most blog posts about "gRPC + Go + Cassandra" skip entirely, and it's arguably the most important architectural decision in the whole stack. Kafka isn't an add-on here. It's the central nervous system.
Why Kafka Sits Between the Feeds and Everything Else
The feed handlers connect to exchanges (FIX, WebSocket, proprietary protocols), normalize the raw data into protobuf messages, and produce to Kafka topics. They don't write to Cassandra. They don't fan out to consumers directly. They just produce to Kafka.
Why?
Decoupling. Without Kafka, a feed handler that connects to the CME needs to know about every downstream consumer - the Cassandra writer, the risk engine, the analytics pipeline, the client-facing streaming API. When you add a new consumer, you modify the feed handler. When a consumer is slow, it back-pressures the feed handler. When a consumer crashes, the feed handler needs retry logic for that specific consumer. It's a maintenance nightmare that scales linearly with the number of consumers.
With Kafka in the middle, the feed handler has one job: produce protobuf blobs to a topic. Period. Consumers subscribe independently. The risk engine's consumer group can fall behind by 30 seconds without affecting the Cassandra writer's consumer group. A new analytics service can consume from offset 0 and replay the entire day's data without touching the feed handler. A consumer can crash, restart, and resume from its last committed offset without losing a single tick.
Replay and recovery. This is the killer feature for financial data. When the Cassandra writer has a bug that corrupts writes for 15 minutes, you fix the bug, reset the consumer group offset to 15 minutes ago, and replay. The ticks are still in Kafka (we retain 7 days). Try doing that with a direct-write architecture where the feed handler pushes to Cassandra and the data is now scattered across SSTables with incorrect values. You're doing a manual repair at that point.
Backpressure isolation. During market opens and closes, tick rates can spike 10–100x. The feed handlers need to keep up with the exchange feed - if they fall behind, the exchange disconnects them. Kafka absorbs the burst. The Cassandra writer can consume at a steady rate, batching writes efficiently, while Kafka buffers the spikes. The feed handler never blocks, ever.
Audit trail. Regulators love immutable, ordered event logs. Kafka topics with appropriate retention are that log. Every tick, every trade, every order state change is captured in order, with timestamps, and retained for the mandated period.
Protobuf on Kafka - Not Avro, Not JSON
Every byte on every Kafka topic in our system is a serialized protobuf message. Not Avro. Not JSON. Here's why:
Avro requires a schema registry. Confluent's Schema Registry is a fine piece of software, but it's another service to deploy, monitor, and keep available. If the schema registry goes down, producers can't serialize and consumers can't deserialize. In a financial data pipeline running at 100K+ messages/second, that's an outage. Protobuf schemas are compiled into the Go binary at build time. No runtime dependency.
JSON is too expensive. We already covered the serialization benchmarks - 3–7x slower, 6x more allocations, 2.6x larger on the wire. At 100K messages/second, that means ~2.4 million extra allocations per second with JSON (100K × 24 allocations) versus ~400K with protobuf (100K × 4). On a Kafka topic with 30 partitions, each partition's consumers are independently paying that cost.
Protobuf gives us one schema everywhere. The same PriceUpdate message definition generates Go structs used by gRPC, Kafka producers, Kafka consumers, and gocql writes. No translation layers. The feed handler marshals a PriceUpdate to bytes, produces those bytes to Kafka, and the consumer on the other end unmarshals the same bytes back into the same Go struct. Zero impedance mismatch.
The one legitimate criticism of protobuf on Kafka: messages aren't self-describing. A consumer needs the compiled proto to decode them. We handle this by versioning topics (e.g., ticks.raw.v2) and ensuring all consumers in a consumer group are built against the same proto version. In practice, protobuf's backward/forward compatibility (don't reuse field numbers, only add optional fields) means this rarely matters.
Topic Design and Partitioning
Topic partitioning strategy is where financial domain knowledge meets Kafka internals:
Topic: ticks.raw
Partitions: 64
Replication: 3
Retention: 7 days
Key: exchange|symbol (e.g., "NASDAQ|AAPL")
Value: protobuf PriceUpdate bytes
Topic: trades.executed
Partitions: 32
Replication: 3
Retention: 30 days
Key: account_id
Value: protobuf ExecutionReport bytes
Topic: orders.lifecycle
Partitions: 32
Replication: 3
Retention: 30 days
Key: order_id
Value: protobuf OrderStatusUpdate bytes
Topic: positions.updates
Partitions: 16
Replication: 3
Retention: 7 days
Key: account_id|symbol
Value: protobuf PositionUpdate bytesThe partition key choice is critical:
ticks.raw keyed by exchange|symbol: All ticks for AAPL on NASDAQ go to the same partition. This guarantees ordering per symbol - tick T+1 always arrives after tick T for the same instrument. Consumers can process each partition independently with the guarantee that no reordering has occurred. With 64 partitions and ~5,000 active symbols, you get decent distribution while keeping high-volume symbols in order.
trades.executed keyed by account_id: All trades for a given account land in the same partition. This means the Cassandra writer can batch writes by account (which maps to the Cassandra partition key (account_id, trade_date)), and downstream consumers like the position service see a consistent, ordered stream of trades per account.
orders.lifecycle keyed by order_id: All state transitions for a single order are in the same partition. NEW → PARTIAL → FILLED arrives in order. This is essential for any consumer maintaining order state.
Tick Lifecycle: From Exchange to Cassandra
Here's the full lifecycle of a single market data tick through the system, with approximate latency at each stage:
Consumer Groups: Independent Consumers, Shared Topics
Each downstream service runs its own Kafka consumer group. They all read from the same topics but maintain independent offsets. This is what makes the architecture resilient - the Cassandra writer falling behind doesn't affect the risk engine, and vice versa:
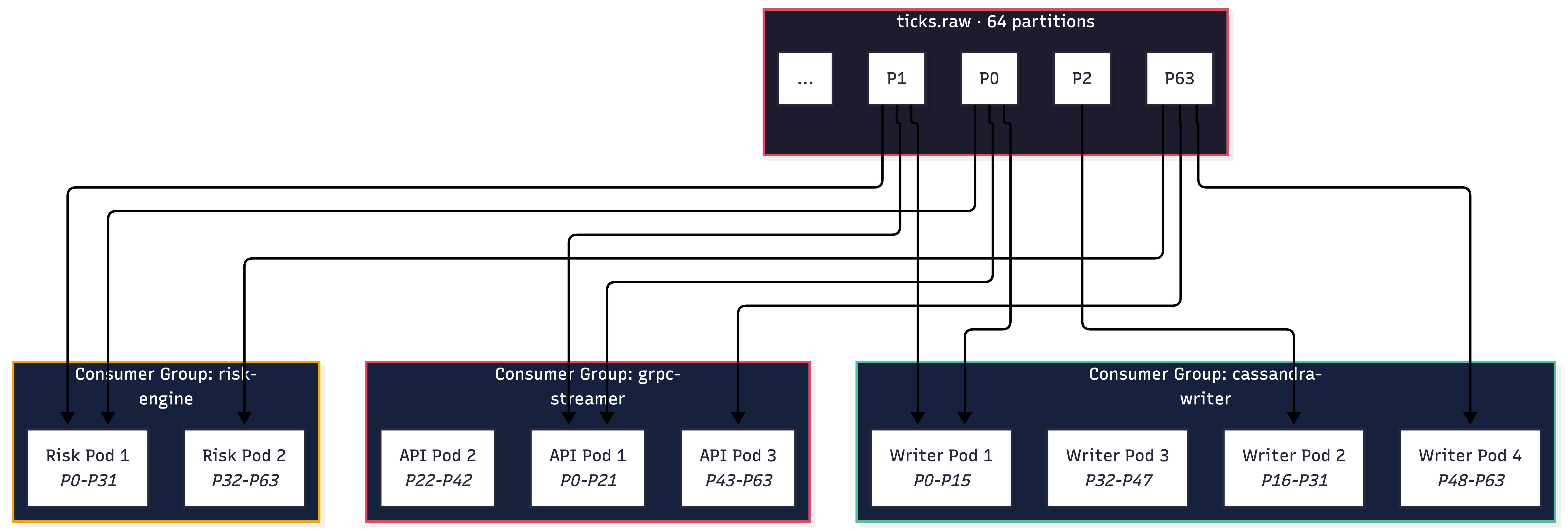
Each consumer group scales independently. During market opens when tick rate spikes 10–100x, you scale the cassandra-writer group from 4 to 8 pods. Kafka rebalances partitions automatically (sticky assignment minimizes disruption). The risk engine and API streamer groups are unaffected. This is the operational power of Kafka as a backbone - you scale each consumer tier based on its bottleneck, not the bottleneck of the entire pipeline.
The Producer: Feed Handler → Kafka
We use the Shopify/sarama library - it's the most mature Go Kafka client, battle-tested at Shopify's scale. The producer configuration for a low-latency financial pipeline:
import (
"github.com/Shopify/sarama"
"google.golang.org/protobuf/proto"
pb "github.com/yourorg/financial-platform/gen/proto/marketdata/v1"
)
func NewTickProducer(brokers []string, logger *zap.Logger) (sarama.AsyncProducer, error) {
config := sarama.NewConfig()
// Producer tuning for low-latency financial data
config.Producer.RequiredAcks = sarama.WaitForAll // acks=all for durability
config.Producer.Retry.Max = 5
config.Producer.Retry.Backoff = 100 * time.Millisecond
// Compression - LZ4 gives the best latency/ratio tradeoff
config.Producer.Compression = sarama.CompressionLZ4
// Batching - critical tradeoff between latency and throughput
// Flush after 100 messages OR 5ms, whichever comes first
config.Producer.Flush.Messages = 100
config.Producer.Flush.Frequency = 5 * time.Millisecond
config.Producer.Flush.MaxMessages = 500
// Channel buffer for async producer
config.ChannelBufferSize = 4096
// Partitioner - hash on key for consistent symbol → partition mapping
config.Producer.Partitioner = sarama.NewHashPartitioner
// Return successes and errors for monitoring
config.Producer.Return.Successes = true
config.Producer.Return.Errors = true
// TLS
config.Net.TLS.Enable = true
config.Net.TLS.Config = loadKafkaTLSConfig()
// SASL if needed (common in managed Kafka / Strimzi with OAuth)
// config.Net.SASL.Enable = true
// config.Net.SASL.Mechanism = sarama.SASLTypeSCRAMSHA512
producer, err := sarama.NewAsyncProducer(brokers, config)
if err != nil {
return nil, fmt.Errorf("creating kafka producer: %w", err)
}
// Error/success handler goroutines
go func() {
for err := range producer.Errors() {
logger.Error("kafka produce error",
zap.String("topic", err.Msg.Topic),
zap.Error(err.Err),
)
kafkaProduceErrors.Inc() // prometheus counter
}
}()
go func() {
for msg := range producer.Successes() {
kafkaProduceLatency.Observe(
time.Since(msg.Metadata.(time.Time)).Seconds(),
)
}
}()
return producer, nil
}
// ProduceTick serializes a PriceUpdate to protobuf and sends to Kafka.
// This is called by the feed handler for every normalized tick.
func ProduceTick(producer sarama.AsyncProducer, tick *pb.PriceUpdate) error {
// Marshal protobuf - ~557-875 ns
value, err := proto.Marshal(tick)
if err != nil {
return fmt.Errorf("marshaling tick: %w", err)
}
// Partition key: exchange|symbol for per-symbol ordering
key := tick.Exchange + "|" + tick.Symbol
producer.Input() <- &sarama.ProducerMessage{
Topic: "ticks.raw",
Key: sarama.StringEncoder(key),
Value: sarama.ByteEncoder(value), // raw protobuf bytes
Metadata: time.Now(), // for latency tracking
}
return nil
}Note the batching configuration. Flush.Frequency = 5ms means the producer accumulates messages for up to 5 milliseconds before sending a batch to the broker. This adds 0–5ms of latency (average 2.5ms) but dramatically improves throughput by reducing the number of network round-trips to Kafka. For a financial data pipeline where you're measuring end-to-end in single-digit milliseconds, this is an acceptable tradeoff. If you set it to 0 (send immediately), you'll get lower latency per message but the broker will buckle under the request rate at high volumes.
The Consumer: Kafka → Cassandra Writer
The Cassandra writer service is a dedicated Go process whose only job is to consume protobuf messages from Kafka and write them to Cassandra. It runs as its own Kubernetes Deployment, separate from the gRPC API services. This is the core of the persistence pipeline:
import (
"context"
"sync"
"time"
"github.com/Shopify/sarama"
"github.com/gocql/gocql"
"go.uber.org/zap"
"google.golang.org/protobuf/proto"
pb "github.com/yourorg/financial-platform/gen/proto/marketdata/v1"
)
// CassandraTickWriter consumes from Kafka and writes to Cassandra.
// It implements sarama.ConsumerGroupHandler.
type CassandraTickWriter struct {
session *gocql.Session
logger *zap.Logger
batchSize int
flushInterval time.Duration
}
func NewCassandraTickWriter(session *gocql.Session, logger *zap.Logger) *CassandraTickWriter {
return &CassandraTickWriter{
session: session,
logger: logger,
batchSize: 200, // flush every 200 ticks
flushInterval: 50 * time.Millisecond, // or every 50ms
}
}
// Setup is called at the beginning of a new consumer group session.
func (w *CassandraTickWriter) Setup(sarama.ConsumerGroupSession) error {
w.logger.Info("consumer group session started")
return nil
}
// Cleanup is called at the end of a consumer group session.
func (w *CassandraTickWriter) Cleanup(sarama.ConsumerGroupSession) error {
w.logger.Info("consumer group session ended")
return nil
}
// ConsumeClaim processes messages from a single Kafka partition.
// Each partition gets its own goroutine - this is where the work happens.
func (w *CassandraTickWriter) ConsumeClaim(
session sarama.ConsumerGroupSession,
claim sarama.ConsumerGroupClaim,
) error {
// Buffer for micro-batching writes to Cassandra
buffer := make([]*pb.PriceUpdate, 0, w.batchSize)
ticker := time.NewTicker(w.flushInterval)
defer ticker.Stop()
flush := func() {
if len(buffer) == 0 {
return
}
start := time.Now()
if err := w.writeBatch(buffer); err != nil {
w.logger.Error("batch write failed",
zap.Int("batch_size", len(buffer)),
zap.Error(err),
)
cassandraWriteErrors.Inc()
// Don't commit offsets - messages will be redelivered
return
}
cassandraWriteLatency.Observe(time.Since(start).Seconds())
cassandraWriteBatchSize.Observe(float64(len(buffer)))
// Mark the last message in the batch as processed.
// sarama commits offsets asynchronously.
session.MarkMessage(
claim.Messages()[len(buffer)-1], // doesn't work like this, simplified
"",
)
buffer = buffer[:0] // reset without dealloc
}
for {
select {
case msg, ok := <-claim.Messages():
if !ok {
flush() // partition revoked, flush remaining
return nil
}
// Deserialize protobuf - ~599-650 ns
tick := &pb.PriceUpdate{}
if err := proto.Unmarshal(msg.Value, tick); err != nil {
w.logger.Error("failed to unmarshal tick",
zap.Int64("offset", msg.Offset),
zap.Int32("partition", msg.Partition),
zap.Error(err),
)
// Mark as consumed anyway - bad messages shouldn't block the pipeline.
// Send to a dead letter topic for investigation.
session.MarkMessage(msg, "")
continue
}
buffer = append(buffer, tick)
if len(buffer) >= w.batchSize {
flush()
}
// Mark every message individually for accurate offset tracking
session.MarkMessage(msg, "")
case <-ticker.C:
flush() // time-based flush for low-volume periods
case <-session.Context().Done():
flush()
return nil
}
}
}
// writeBatch groups ticks by Cassandra partition key and writes
// unlogged batches for efficiency.
func (w *CassandraTickWriter) writeBatch(ticks []*pb.PriceUpdate) error {
// Group by Cassandra partition key: (exchange, symbol, trade_date)
partitions := make(map[string][]*pb.PriceUpdate)
tradeDate := time.Now().Format("2006-01-02")
for _, tick := range ticks {
key := tick.Exchange + "|" + tick.Symbol + "|" + tradeDate
partitions[key] = append(partitions[key], tick)
}
// Write one unlogged batch per Cassandra partition.
// Unlogged batches to the same partition are efficient -
// they hit a single replica set and avoid the batchlog overhead.
var writeErr error
for _, group := range partitions {
batch := w.session.NewBatch(gocql.UnloggedBatch)
batch.SetConsistency(gocql.LocalOne)
for _, tick := range group {
batch.Query(`
INSERT INTO tick_data (exchange, symbol, trade_date, tick_time,
bid_micros, ask_micros, last_micros, volume)
VALUES (?, ?, ?, now(), ?, ?, ?, ?)`,
tick.Exchange,
tick.Symbol,
tradeDate,
tick.BidMicros,
tick.AskMicros,
tick.LastMicros,
tick.Volume,
)
}
if err := w.session.ExecuteBatch(batch); err != nil {
w.logger.Error("cassandra batch failed",
zap.String("partition_key", group[0].Exchange+"|"+group[0].Symbol),
zap.Int("batch_size", len(group)),
zap.Error(err),
)
writeErr = err
// Continue with other partitions - don't let one bad partition
// block the entire batch
}
}
return writeErr
}
// RunConsumerGroup starts the Kafka consumer group loop.
// This blocks until the context is cancelled.
func RunConsumerGroup(
ctx context.Context,
brokers []string,
groupID string,
topics []string,
handler sarama.ConsumerGroupHandler,
logger *zap.Logger,
) error {
config := sarama.NewConfig()
config.Version = sarama.V2_6_0_0 // match your Kafka cluster version
config.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategySticky
config.Consumer.Offsets.Initial = sarama.OffsetNewest
config.Consumer.Offsets.AutoCommit.Enable = true
config.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second
// Fetch tuning - larger fetches = higher throughput, more memory
config.Consumer.Fetch.Min = 1024 // 1KB minimum fetch
config.Consumer.Fetch.Default = 1048576 // 1MB default fetch
config.Consumer.Fetch.Max = 10485760 // 10MB max fetch
config.Consumer.MaxProcessingTime = 5 * time.Second
// TLS - must match Strimzi listener configuration
config.Net.TLS.Enable = true
config.Net.TLS.Config = loadKafkaTLSConfig()
group, err := sarama.NewConsumerGroup(brokers, groupID, config)
if err != nil {
return fmt.Errorf("creating consumer group: %w", err)
}
defer group.Close()
// Consumer group error handler
go func() {
for err := range group.Errors() {
logger.Error("consumer group error", zap.Error(err))
}
}()
// Consume loop - sarama handles rebalancing automatically.
// When partitions are revoked/assigned, Setup/Cleanup are called.
for {
if err := group.Consume(ctx, topics, handler); err != nil {
logger.Error("consumer group consume error", zap.Error(err))
}
if ctx.Err() != nil {
return ctx.Err()
}
}
}A few things to call out about this design:
Micro-batching on the consumer side. The writer accumulates ticks in a buffer and flushes either when the buffer hits 200 messages or every 50ms, whichever comes first. This lets us use Cassandra unlogged batches grouped by partition key, which is the most efficient write pattern. A batch of 50 ticks to the same (exchange, symbol, trade_date) partition is nearly as fast as a single write - Cassandra sends them all to the same replica in one network round-trip.
BalanceStrategySticky for partition assignment. During consumer group rebalances (when you scale the writer service up or down), sticky assignment minimizes the number of partitions that move between consumers. This reduces the "rebalance storm" problem where all consumers stop processing while assignments shuffle. Sticky assignment was a significant improvement over the range/round-robin strategies.
Offset commit after successful Cassandra write. If the Cassandra write fails, we don't commit the offset. The messages will be redelivered on the next poll. This gives us at-least-once delivery semantics. For tick data (which is idempotent - writing the same tick twice is harmless), this is exactly what we want. For trade executions, the Cassandra table uses INSERT IF NOT EXISTS or a deduplication column to handle replays.
Dead letter handling for bad messages. A corrupt protobuf message shouldn't block the entire pipeline. We log it, mark it as consumed, and move on. In a more sophisticated setup, you'd produce it to a ticks.raw.dlq topic for later investigation.
Cassandra 3.11 for Financial Time-Series
Cassandra 3.11 is the production workhorse right now. The 3.x line brought a complete storage engine rewrite - SSTables are now CQL-aware, storing partitions and rows as first-class citizens instead of the old Thrift-centric layout.
For financial data, Cassandra's value proposition is simple: it's write-optimized by design. Market data ingestion, trade recording, order book updates - these are all fundamentally append-only workloads. Cassandra writes to an in-memory memtable plus a sequential commit log. No read-before-write. No random disk I/O. Median write latency is ~73 microseconds locally. At the client with CONSISTENCY ONE, you're looking at 0.5–2ms.
Data Modeling for Tick Data
The cardinal rule: design tables around query patterns, not entity relationships. Target partition sizes under 100MB and ideally under 100,000 rows. For high-volume instruments, time-based bucketing in the partition key is essential:
-- ===========================================================
-- TICK DATA
-- One partition per exchange + symbol + date
-- Clustering by timeuuid gives sub-millisecond ordering
-- Written by the dedicated Kafka → Cassandra writer service
-- ===========================================================
CREATE TABLE IF NOT EXISTS market_data.tick_data (
exchange text,
symbol text,
trade_date text, -- '2020-03-15' format
tick_time timeuuid, -- sub-ms ordering, conflict-free
bid_micros bigint, -- price * 1,000,000
ask_micros bigint,
last_micros bigint,
volume int,
PRIMARY KEY((exchange, symbol, trade_date), tick_time)
) WITH CLUSTERING ORDER BY (tick_time DESC)
AND compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_unit': 'HOURS',
'compaction_window_size': 1
}
AND compression = {
'class': 'LZ4Compressor',
'chunk_length_in_kb': 64
}
AND bloom_filter_fp_chance = 0.01
AND dclocal_read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE'
AND default_time_to_live = 7776000; -- 90 days TTL
-- ===========================================================
-- TRADE EXECUTIONS
-- Partitioned by account + date for per-account queries
-- ===========================================================
CREATE TABLE IF NOT EXISTS market_data.trade_executions (
account_id text,
trade_date text,
execution_time timestamp,
trade_id timeuuid,
symbol text,
side text,
quantity_micros bigint,
price_micros bigint,
fees_micros bigint,
venue text,
PRIMARY KEY((account_id, trade_date), execution_time, trade_id)
) WITH CLUSTERING ORDER BY (execution_time DESC, trade_id DESC)
AND compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_unit': 'DAYS',
'compaction_window_size': 1
};
-- ===========================================================
-- ORDER BOOK SNAPSHOTS
-- Hourly snapshots for L2 reconstruction
-- ===========================================================
CREATE TABLE IF NOT EXISTS market_data.order_book_snapshots (
exchange text,
symbol text,
snapshot_hour text, -- '2020-03-15T14' format
snapshot_time timestamp,
depth_level int,
bid_micros bigint,
bid_size bigint,
ask_micros bigint,
ask_size bigint,
PRIMARY KEY((exchange, symbol, snapshot_hour), snapshot_time, depth_level)
) WITH CLUSTERING ORDER BY (snapshot_time DESC, depth_level ASC)
AND compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_unit': 'HOURS',
'compaction_window_size': 1
};
-- ===========================================================
-- EVENT STORE (for event-sourced aggregates)
-- ===========================================================
CREATE TABLE IF NOT EXISTS market_data.event_store (
entity_type text,
entity_id text,
event_time timeuuid,
event_type text,
payload blob, -- protobuf-serialized event
metadata map<text, text>,
PRIMARY KEY((entity_type, entity_id), event_time)
) WITH CLUSTERING ORDER BY (event_time ASC);Design decisions worth calling out:
timeuuid for tick ordering: Regular timestamps have millisecond precision. In a market data feed, you can easily receive multiple ticks for the same symbol within a single millisecond. timeuuid gives you sub-millisecond ordering with guaranteed uniqueness.
CLUSTERING ORDER BY (tick_time DESC): Aligns on-disk sort with the most common query (most-recent-first). No sort overhead at read time.
dclocal_read_repair_chance = 0.0: Read repair on time-series tables is actively harmful. It pulls old data into the current memtable, confusing TWCS windows. Disable it. Run nodetool repair on a schedule.
bloom_filter_fp_chance = 0.01: Burns more memory but eliminates almost all unnecessary SSTable reads. DoorDash had an outage when they changed compaction strategies without adjusting bloom filter settings - the higher false positive rate caused enough extra reads to OOM their nodes.
speculative_retry = '99PERCENTILE': Demolishes tail latency by automatically firing a second read to another replica when the first exceeds p99. A no-brainer for financial queries.
TimeWindowCompactionStrategy
TWCS is the compaction strategy for financial time-series data. Period.
| Strategy | Write Amplification | Read Amplification | Space Overhead | When To Use |
|---|---|---|---|---|
| STCS (SizeTiered) | Low | High (many SSTables) | ~50% free disk | Bulk historical loads |
| LCS (Leveled) | High (10–30x rewrites) | Low (1–2 SSTables/read) | ~10% | Reference data |
| TWCS | Low | Low for time-range queries | Minimal | Tick data, trades |
TWCS groups SSTables into time windows (1 hour for intraday ticks). Within the active window, it uses size-tiered compaction. Once a window closes, all SSTables for that window get compacted into a single SSTable and are never touched again. When TTL expires, entire SSTables drop as a unit - no tombstone scanning. One team I worked with reduced their SSTable count from over 1,000 to ~50 after switching from STCS to TWCS.
Here's how TWCS windows work over the course of a trading day:
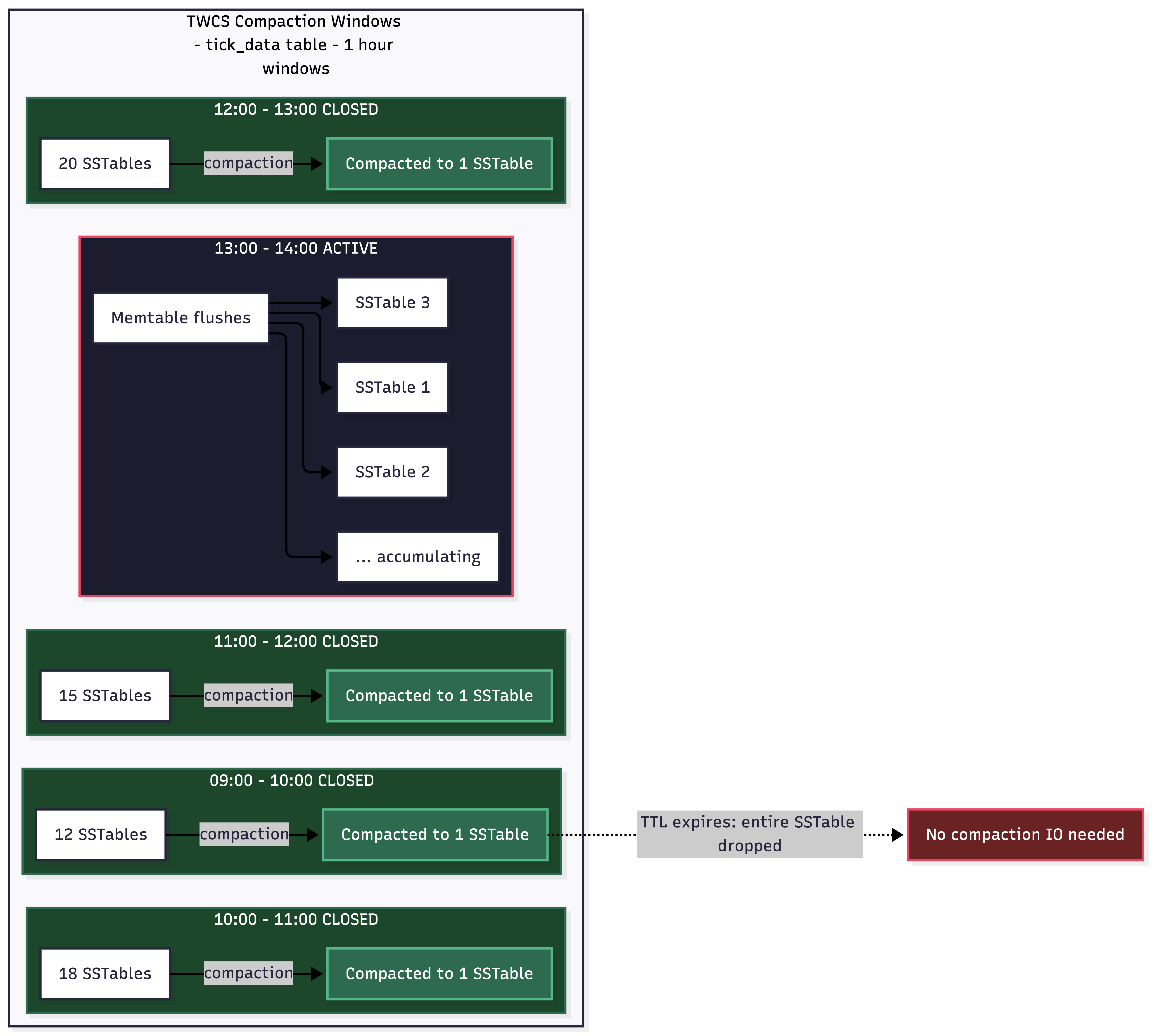
The key insight: closed windows produce exactly one SSTable each. Reads spanning a 4-hour range hit at most 4 SSTables (one per window) plus whatever's in the active window's memtable. Compare that to STCS where you might scan 50+ SSTables for the same range. And when the 90-day TTL expires, entire SSTables drop wholesale - no tombstone scanning, no compaction I/O.
Critical assumption: data is append-only with no out-of-order writes. Financial tick data matches this perfectly. This is also why the Kafka → Cassandra pipeline works so well - Kafka guarantees per-partition ordering, and the writer consumes in order.
Consistency Levels for Financial Deployments
CREATE KEYSPACE IF NOT EXISTS financial_data
WITH replication = {
'class': 'NetworkTopologyStrategy',
'dc-london': 3,
'dc-newyork': 3
};| Operation | Consistency Level | Rationale |
|---|---|---|
| Tick data writes (via Kafka consumer) | LOCAL_ONE | Maximum throughput, immutable, duplicates harmless |
| Tick data reads (via gRPC API) | LOCAL_QUORUM | Must read committed data |
| Trade execution writes | LOCAL_QUORUM | Must be durable before ack |
| Trade execution reads | LOCAL_QUORUM | Cannot serve stale trades |
| Audit trail writes | EACH_QUORUM | Regulatory cross-DC durability |
| Reference data reads | LOCAL_ONE | Rarely changes |
Tuning Parameters That Actually Matter
cassandra.yaml:
memtable_heap_space_in_mb: 2048
memtable_offheap_space_in_mb: 2048
commitlog_segment_size_in_mb: 64
commitlog_sync: periodic
commitlog_sync_period_in_ms: 10000
concurrent_reads: 64
concurrent_writes: 128
concurrent_compactors: 4
key_cache_size_in_mb: 512
row_cache_size_in_mb: 0 # DISABLED for time-seriesJVM (jvm.options):
-Xms16G
-Xmx16G
-XX:+UseG1GC
-XX:MaxGCPauseMillis=500
-XX:InitiatingHeapOccupancyPercent=70OS:
vm.swappiness = 1
echo 'none' > /sys/block/nvme0n1/queue/scheduler
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defragGo 1.12–1.14: What Changed and Why It Matters
Three Go releases landed in 2019–2020 that directly improved this stack.
Go 1.12 (February 2019): Opt-in TLS 1.3, improved GC memory scavenging (critical for K8s cgroup limits - before 1.12, Go was bad at returning memory to the OS, which meant Kubernetes would OOM-kill pods even when live heap was well under the limit).
Go 1.13 (September 2019): TLS 1.3 default, errors.Is/errors.As/errors.Unwrap for proper error chain inspection (matters when you need to distinguish "Kafka broker unreachable" from "Cassandra cluster overloaded" five layers deep), defer improved ~30%.
Go 1.14 (February 2020): defer near-zero overhead, asynchronous goroutine preemption - the big one. Before 1.14, a goroutine in a tight CPU loop (risk calculation) could starve the scheduler indefinitely, delaying GC and blocking other goroutines including your Kafka consumers. Now the runtime preempts at almost any point.
Go's GC and Why It Matters
Go's concurrent tri-color mark-and-sweep GC delivers sub-millisecond pauses - American Express reported production pauses of ~250µs to 1ms. Compare that to Java G1GC's typical 10–100ms pauses. This is the single biggest reason I chose Go over Java. A 50ms GC pause means 50ms where your Kafka consumer isn't polling, your Cassandra writer isn't flushing, and your gRPC stream isn't sending. Go makes this a non-issue.
Tuning: GOGC=75 for financial services. The gocql driver docs explicitly recommend tuning this because unmarshaling Cassandra results incurs heavy allocations. Same applies to protobuf unmarshal on the Kafka consumer path.
Goroutines: Why Concurrency is Cheap
A goroutine starts with 2KB stack versus 1–8MB for a Java thread. Handling 10,000 concurrent gRPC connections + 64 Kafka partition consumers + Cassandra connection pools costs ~20MB of stack. The Go M:N scheduler handles the multiplexing. No thread pool tuning, no reactive programming frameworks, no CompletableFuture chains. You just go handlePartition(claim) and move on.
Deployment: Docker, Kubernetes, Strimzi, and Cloud Infrastructure
Containerizing Go Services
Multi-stage Docker builds. The production image is scratch or distroless:
FROM golang:1.14-alpine AS builder
RUN apk add --no-cache git ca-certificates
WORKDIR /src
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 \
go build -ldflags="-w -s" -o /bin/marketdata-service ./cmd/server
FROM gcr.io/distroless/static:nonroot
COPY --from=builder /bin/marketdata-service /
EXPOSE 50051 9090
USER nonroot:nonroot
ENTRYPOINT ["/marketdata-service"]Build image: 729MB. Production image: ~8MB. That's not a typo. A Go gRPC service with Kafka and Cassandra connectivity in an 8MB container that starts in under a second. Compare that to a 300MB+ JVM-based image that takes 15–30 seconds to warm up.
Kubernetes Deployment Topology
Here's how all the pieces lay out across a Kubernetes cluster. Each stateful component (Kafka, ZooKeeper, Cassandra) gets its own dedicated node pool with local NVMe SSDs. Go services run on a shared compute pool and autoscale independently:
Each pod anti-affinity rule ensures one Kafka broker per node, one Cassandra instance per node, and one ZooKeeper per node. The compute pool is where all the Go services run - these are stateless and horizontally scalable via HPA. During market opens, the cassandra-writer Deployment might scale from 4 to 8 pods based on Kafka consumer lag metrics.
Kafka on Kubernetes with Strimzi
Strimzi is how we run Kafka on Kubernetes. It's a CNCF sandbox project that provides a Kafka operator managing brokers, ZooKeeper, topics, users, and Connect through CRDs. This is dramatically simpler than deploying Kafka manually on K8s, and it handles the stateful set management, rolling upgrades, rack awareness, and certificate rotation that would otherwise consume an entire team's time.
# Strimzi Kafka cluster for financial data
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: financial-cluster
namespace: kafka
spec:
kafka:
version: 2.6.0
replicas: 3
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: tls
config:
# Replication
default.replication.factor: 3
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
# Performance tuning for low-latency
num.network.threads: 8
num.io.threads: 16
socket.send.buffer.bytes: 1048576 # 1MB
socket.receive.buffer.bytes: 1048576
socket.request.max.bytes: 104857600 # 100MB
# Log retention - 7 days for ticks, override per topic
log.retention.hours: 168
log.segment.bytes: 1073741824 # 1GB segments
log.retention.check.interval.ms: 300000
# Compression
compression.type: lz4
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 500Gi
class: local-ssd
deleteClaim: false
resources:
requests:
memory: 8Gi
cpu: "4"
limits:
memory: 16Gi
cpu: "8"
jvmOptions:
-Xms: 4096m
-Xmx: 4096m
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: strimzi.io/name
operator: In
values:
- financial-cluster-kafka
topologyKey: kubernetes.io/hostname
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-metrics-config.yml
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 50Gi
class: local-ssd
resources:
requests:
memory: 2Gi
cpu: "1"
limits:
memory: 4Gi
cpu: "2"
entityOperator:
topicOperator: {}
userOperator: {}
---
# Topic definitions as CRDs - version controlled, declarative
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: ticks-raw
labels:
strimzi.io/cluster: financial-cluster
spec:
partitions: 64
replicas: 3
config:
retention.ms: 604800000 # 7 days
cleanup.policy: delete
compression.type: lz4
min.insync.replicas: 2
segment.bytes: 1073741824 # 1GB
# Slightly larger segment index for high-throughput topics
segment.index.bytes: 52428800 # 50MB
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: trades-executed
labels:
strimzi.io/cluster: financial-cluster
spec:
partitions: 32
replicas: 3
config:
retention.ms: 2592000000 # 30 days
cleanup.policy: delete
compression.type: lz4
min.insync.replicas: 2
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: orders-lifecycle
labels:
strimzi.io/cluster: financial-cluster
spec:
partitions: 32
replicas: 3
config:
retention.ms: 2592000000 # 30 days
cleanup.policy: delete
compression.type: lz4
min.insync.replicas: 2Things I've learned running Strimzi in production:
min.insync.replicas: 2 with acks=all and replication.factor: 3: This means a produce succeeds when 2 of 3 replicas acknowledge. One broker can be down for maintenance without blocking producers. This is the sweet spot for durability vs. availability. min.insync.replicas: 3 means zero tolerance for any broker being unavailable, which makes rolling upgrades impossible without downtime.
Local SSDs for Kafka storage. Kafka is I/O-bound. The NVMe SSDs on i3 instances (same hardware we use for Cassandra) give us the sequential write throughput Kafka needs. The local-ssd StorageClass maps to local NVMe PersistentVolumes provisioned by a local volume provisioner.
Pod anti-affinity is mandatory. All three brokers on the same node means a single node failure kills your cluster. requiredDuringSchedulingIgnoredDuringExecution makes this a hard constraint, not a preference.
JMX Prometheus exporter built into Strimzi. Strimzi has first-class support for Prometheus metrics. The metricsConfig section above tells the operator to inject a JMX exporter sidecar. No manual JMX configuration.
KafkaTopic CRDs are declarative. Topic creation via kubectl apply means topic configurations are version-controlled in Git alongside your service manifests. No more kafka-topics.sh commands that someone runs manually and forgets to document.
Cassandra on Kubernetes
Cassandra on Kubernetes uses StatefulSets with headless services. Several operators are maturing: DataStax Cass Operator (open-sourced May 2020), Orange CassKop (2019), and K8ssandra (launching later in 2020).
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
spec:
serviceName: cassandra
replicas: 3
selector:
matchLabels:
app: cassandra
template:
metadata:
labels:
app: cassandra
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["cassandra"]
topologyKey: kubernetes.io/hostname
terminationGracePeriodSeconds: 1800
containers:
- name: cassandra
image: cassandra:3.11.6
ports:
- containerPort: 9042
name: cql
- containerPort: 7000
name: intra-node
- containerPort: 7199
name: jmx
resources:
requests:
cpu: "4"
memory: "16Gi"
limits:
cpu: "8"
memory: "32Gi"
env:
- name: MAX_HEAP_SIZE
value: "16G"
- name: HEAP_NEWSIZE
value: "3200M"
- name: CASSANDRA_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local"
- name: CASSANDRA_CLUSTER_NAME
value: "financial-cluster"
- name: CASSANDRA_DC
value: "dc-newyork"
- name: CASSANDRA_RACK
value: "rack1"
- name: CASSANDRA_ENDPOINT_SNITCH
value: "GossipingPropertyFileSnitch"
volumeMounts:
- name: cassandra-data
mountPath: /var/lib/cassandra
readinessProbe:
exec:
command: ["/bin/bash", "-c", "nodetool status | grep -E '^UN'"]
initialDelaySeconds: 60
periodSeconds: 10
volumeClaimTemplates:
- metadata:
name: cassandra-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: local-ssd
resources:
requests:
storage: 500Gi
---
apiVersion: v1
kind: Service
metadata:
name: cassandra
spec:
clusterIP: None
selector:
app: cassandra
ports:
- port: 9042
name: cqlCloud Infrastructure
On AWS, i3 instances with NVMe SSDs for both Kafka and Cassandra. The i3.2xlarge (8 vCPUs, 61 GiB RAM, 1.9 TB NVMe) is the sweet spot. Netflix demonstrated SSDs let them replace 48 HDD instances with 15 SSD instances. DataStax Astra just reached GA (May 2020). Amazon Keyspaces launched in April 2020 but it's DynamoDB under the hood, not actual Cassandra - subtle behavioral differences you'll discover at 2 AM. Amazon MSK is the managed Kafka option, but Strimzi gives us more control over broker configuration and avoids MSK's version lag.
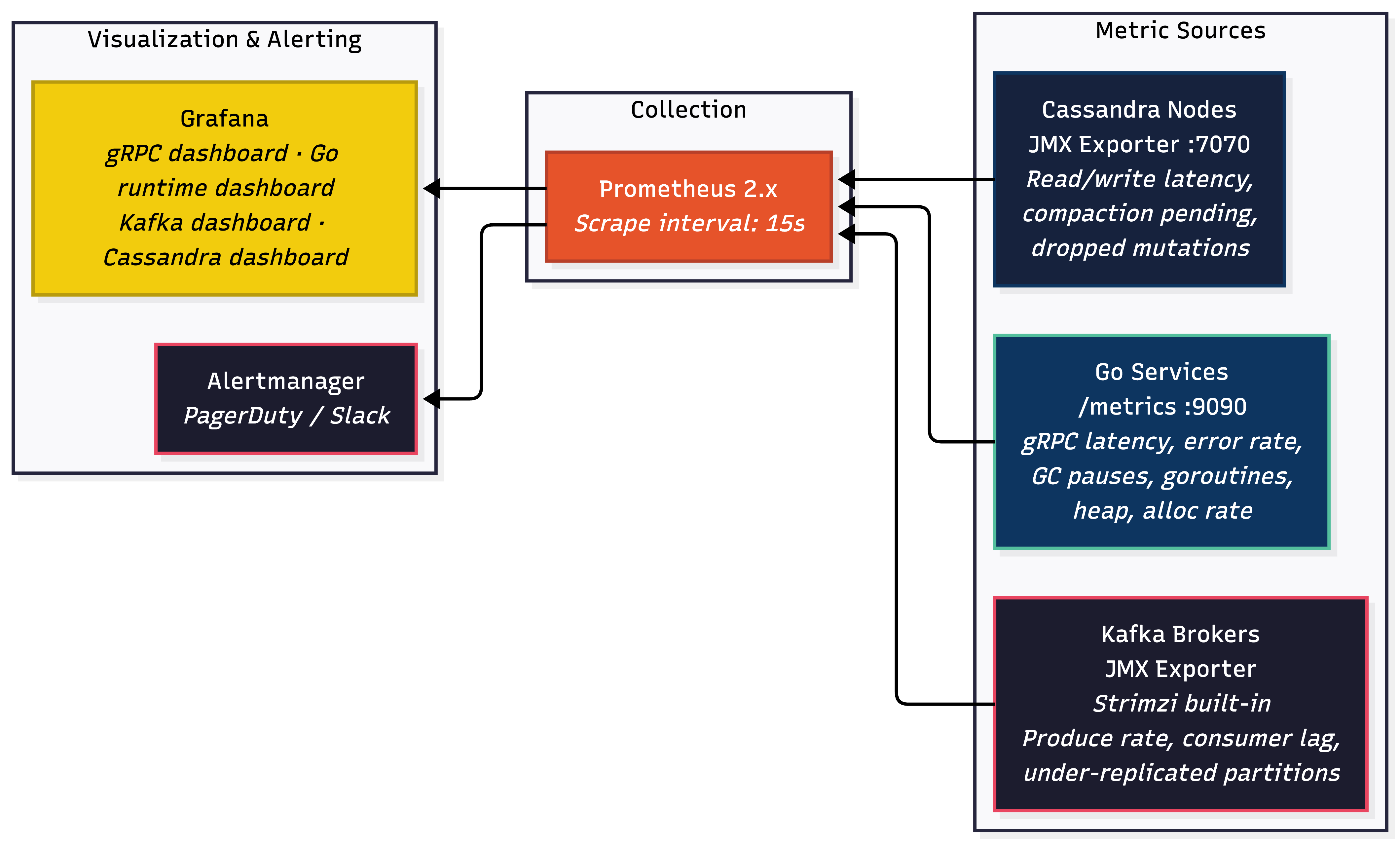
For Kafka specifically, Strimzi's built-in JMX exporter gives you broker metrics for free. The critical alerts for a financial pipeline:
| Metric | Warning | Critical | Why |
|---|---|---|---|
| Consumer group lag (ticks.raw) | > 10,000 | > 100,000 | Cassandra writer falling behind |
| Consumer group lag (trades) | > 100 | > 1,000 | Trade processing delayed |
| Under-replicated partitions | > 0 | > 0 for 5min | Data durability at risk |
| Kafka produce latency p99 | > 10ms | > 50ms | Feed handler bottleneck |
| Kafka request queue size | > 100 | > 500 | Broker overloaded |
| Cassandra read latency p99 | > 25ms | > 100ms | Query performance degraded |
| Cassandra write latency p99 | > 10ms | > 50ms | Writer service bottleneck |
| Compaction pending tasks | > 20 | > 100 | Disk I/O falling behind |
| Go GC pause duration | > 500µs | > 2ms | Latency spikes |
Consumer group lag is the most important metric in the entire system. If the cassandra-writer consumer group lag on ticks.raw starts climbing, it means the writer can't keep up with ingestion. You either need more writer instances (scale the Deployment), more Cassandra write capacity (scale the cluster), or you need to investigate whether compaction or GC is causing the bottleneck. Bursting lag during market opens that recovers within 2–3 minutes is normal. Lag that keeps growing is a fire.
For distributed tracing, Jaeger - written in Go, native OpenTracing support. Use Elasticsearch for the Jaeger backend, not your production Cassandra.
Performance: What You Can Actually Expect
Let me be honest about what this stack delivers end-to-end, with Kafka in the critical path. Kafka adds latency - there's no free lunch. The question is whether the decoupling, replay, and backpressure isolation are worth the extra milliseconds.
Component-Level Latency
| Component | Best Case | Typical p50 | p99 |
|---|---|---|---|
| Protobuf marshal (producer side) | ~557ns | ~875ns | ~2µs |
| Kafka produce (acks=all, LZ4) | 1ms | 2–5ms | 10–15ms |
| Kafka consumer poll + deserialize | 0.5ms | 1–3ms | 5–10ms |
| Go business logic | 50–200µs | 100–500µs | ~1ms |
| Go GC STW pause | ~10µs | ~250µs | ~1ms |
| Cassandra write (LOCAL_ONE, batch) | 0.5ms | 1–2ms | ~5ms |
| Cassandra read (LOCAL_QUORUM, cached) | 1ms | 2–5ms | 10–15ms |
| Cassandra read (LOCAL_QUORUM, disk) | 3ms | 5–15ms | 15–50ms |
| gRPC unary call (incl. network) | 200–500µs | 300–600µs | ~2ms |
End-to-End Pipeline Latency
| Pipeline | p50 | p99 | Throughput |
|---|---|---|---|
| Feed → Kafka → C* writer → Cassandra | 5–12ms | 15–35ms | 100K+ writes/sec |
| Feed → Kafka → gRPC stream to client | 3–8ms | 10–20ms | 400K+ msgs/sec |
| gRPC query → Go → Cassandra read | 5–10ms | 15–50ms | 50K+ reads/sec |
| Full trade lifecycle (order → Kafka → execute → persist → confirm) | 10–20ms | 25–60ms | 10K+ trades/sec |
For Comparison
| Alternative Stack | p50 | p99 | Notes |
|---|---|---|---|
| Java/Spring + REST + PostgreSQL | 10–50ms | 50–200ms | The baseline most teams are upgrading from |
| Same stack without Kafka (direct write) | 2–5ms | 5–15ms | Faster, but no replay/decoupling/backpressure |
| C++/FIX on bare metal | 10–17µs | <100µs | Different universe, 10x engineering cost |
Yes, Kafka adds 2–8ms to the hot path. That's the price of decoupling. In my experience, that price pays for itself the first time you need to replay 15 minutes of tick data because a bug in the writer service corrupted Cassandra writes - which happened twice in the first six months. Without Kafka, those would have been data loss incidents requiring exchange-side reconciliation. With Kafka, they were 20-minute recovery operations. The business value of replay capability vastly outweighs the latency cost for any workload that isn't ultra-high-frequency.
The production evidence for individual components: Netflix linearly scaled Cassandra to 1.1 million writes per second across 288 nodes. LinkedIn pushes 7+ trillion messages per day through Kafka. The go-trader exchange simulator does 410K+ quotes/second through gRPC. These are documented production deployments, not marketing numbers.
Conclusion
The gRPC + Go + Kafka + Cassandra stack, occupies a sweet spot that didn't exist just a year ago.
Kafka is the backbone that makes the architecture operationally sane. It decouples producers from consumers, absorbs traffic spikes during market opens, provides replay capability for recovery, and gives every downstream service an independent, ordered view of the event stream. Running Strimzi on Kubernetes means Kafka lifecycle management - rolling upgrades, scaling, topic management - is declarative and version-controlled, not a collection of shell scripts that someone runs manually and forgets to document.
Protobuf as the universal serialization format - on gRPC, on Kafka topics, in Cassandra blob columns - eliminates the translation layers and schema mismatches that plague multi-transport architectures. One proto definition, one set of generated Go structs, used everywhere. Marshal once at the edge, pass bytes through Kafka, deserialize at the consumer. No JSON-to-Avro-to-protobuf pipeline, no schema registry as a runtime dependency.
Go's sub-millisecond GC pauses and goroutine model make it the right language for services that are simultaneously consuming from Kafka, writing to Cassandra, and serving gRPC streams - all with predictable latency. Go 1.14's asynchronous preemption fixed the last remaining scheduler issue for mixed I/O + computation workloads.
Cassandra's write-optimized LSM engine with TWCS compaction handles the append-only tick data that the Kafka consumers produce. The dedicated gRPC writer service pattern - a single-purpose consumer that owns the Cassandra write path - keeps the persistence layer isolated and independently scalable.
Is it perfect? No. Kafka adds 2–8ms to the hot path. gRPC load balancing still requires Envoy or client-side configuration. Cassandra's operational complexity hasn't gone away. Consumer group rebalances during market opens will give you gray hairs. ZooKeeper is still a single point of failure for Kafka (KRaft mode won't be production-ready until Kafka 3.x).
But for the first time, a small engineering team can build financial data infrastructure that delivers single-digit to low-double-digit-millisecond latency at hundreds of thousands of operations per second, with full event replay capability, independent consumer scaling, and the operational resilience that comes from treating every data flow as an immutable event stream backed by Kafka.
The same Go binary compiles in seconds, deploys as an 8MB container, starts in under a second, and runs predictably without JVM tuning or warm-up time. Kafka and Cassandra deploy via Kubernetes operators with declarative configuration. The entire stack is observable through Prometheus and Grafana. That's the value proposition - not just raw performance, but a system you can actually operate, debug, and recover from when things go wrong at 2:31 PM on a Tuesday.
If you're facing similar challenges, let's talk.
Bring the current architecture context and delivery constraints, and we can map out a focused next step.
Book a Discovery CallNewsletter
Stay connected
Not ready for a call? Get the next post directly.