BLOG POST
Designing a Fintech Backend: Crypto + Open Banking Under One Roof
Why this is hard (and why most existing guides are useless)
Every "fintech architecture" article I've read this year commits the same sin: it treats the crypto side and the banking side as two independent systems with a thin adapter layer in between. That works until the first cross-domain operation. Try executing a crypto-to-fiat transfer where the on-chain swap and the bank payment initiation need to either both succeed or both roll back. Now add compliance checks that span both domains. Now add that the bank API has a 30-second SCA redirect and Ethereum has 12-second block times. Now add that your regulator expects a single audit trail covering both legs of the transaction.
The reality is that you need a unified domain model with specialized adapters, not two systems bolted together. The ledger doesn't care whether a credit came from a Plaid webhook or an Ethereum event log - it cares about double-entry consistency. The compliance engine doesn't care whether a transaction used SEPA or the Polygon bridge - it cares about AML risk scoring. Getting this right requires thinking about the problem from the ledger outward, not from the integrations inward.
The architecture: event-driven microservices with CQRS
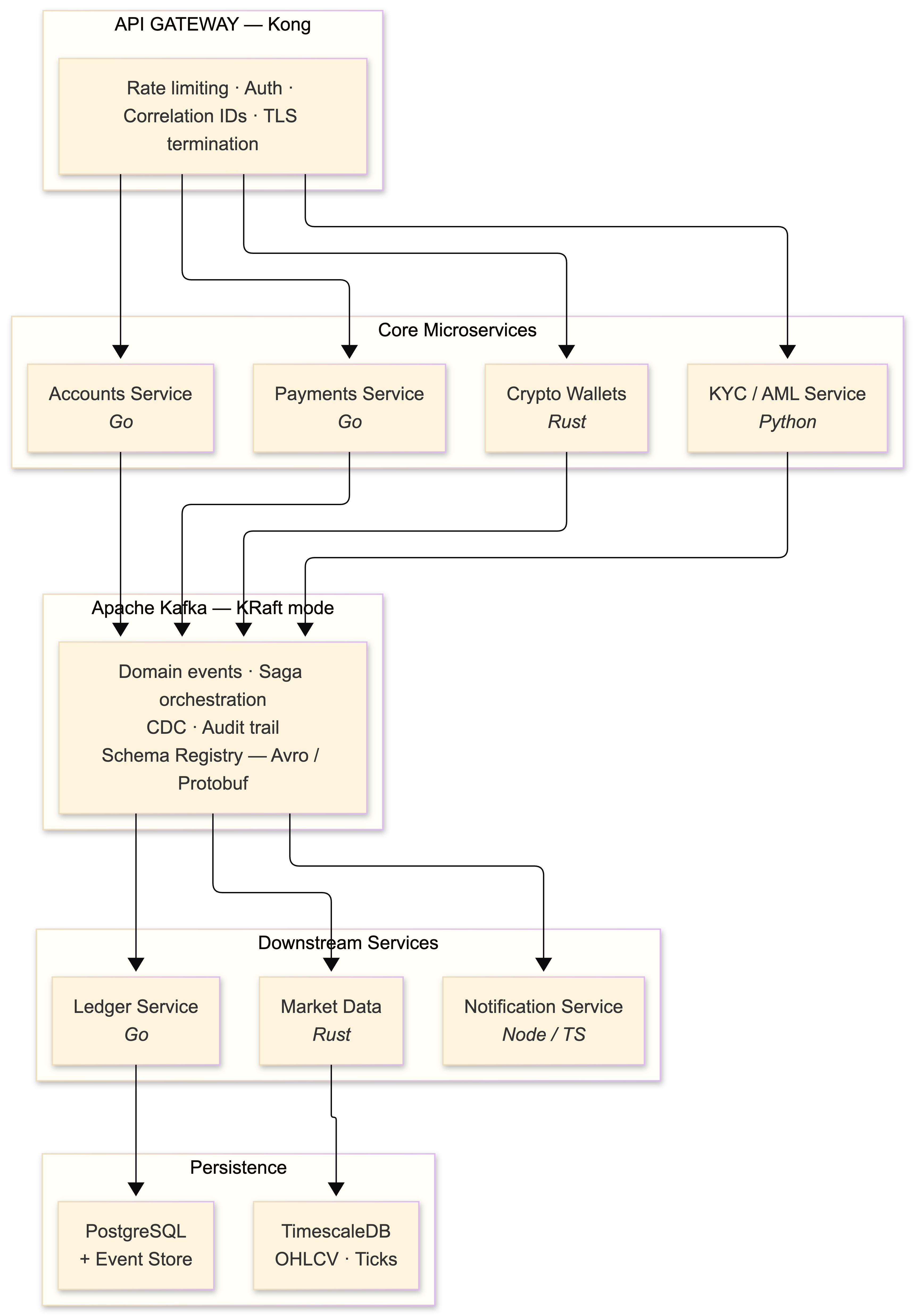
The platform decomposes into bounded contexts straight out of DDD: Accounts, Payments, Ledger, Crypto Wallets, Market Data, KYC/AML, and Notifications. Each one is an independent microservice. I run these on Kubernetes 1.24 (which, heads up, removed Dockershim - make sure your container runtime is containerd or CRI-O before upgrading).
The architectural spine is event-driven with Apache Kafka serving as the central nervous system. I'm running Kafka 3.2 with KRaft mode in staging (the ZooKeeper removal is real and it's coming - start planning). Every state change emits a domain event: bank account linked, payment initiated, crypto transaction signed, KYC status updated. Downstream services consume these events for their own projections and workflows.
Two patterns coexist here, and the distinction matters:
Choreography handles loosely-coupled flows. The Notification Service listens to payments.transaction.completed and sends a push notification. The Analytics Service consumes the same event and updates dashboards. Neither knows about the other, and neither can break the payment flow if it fails.
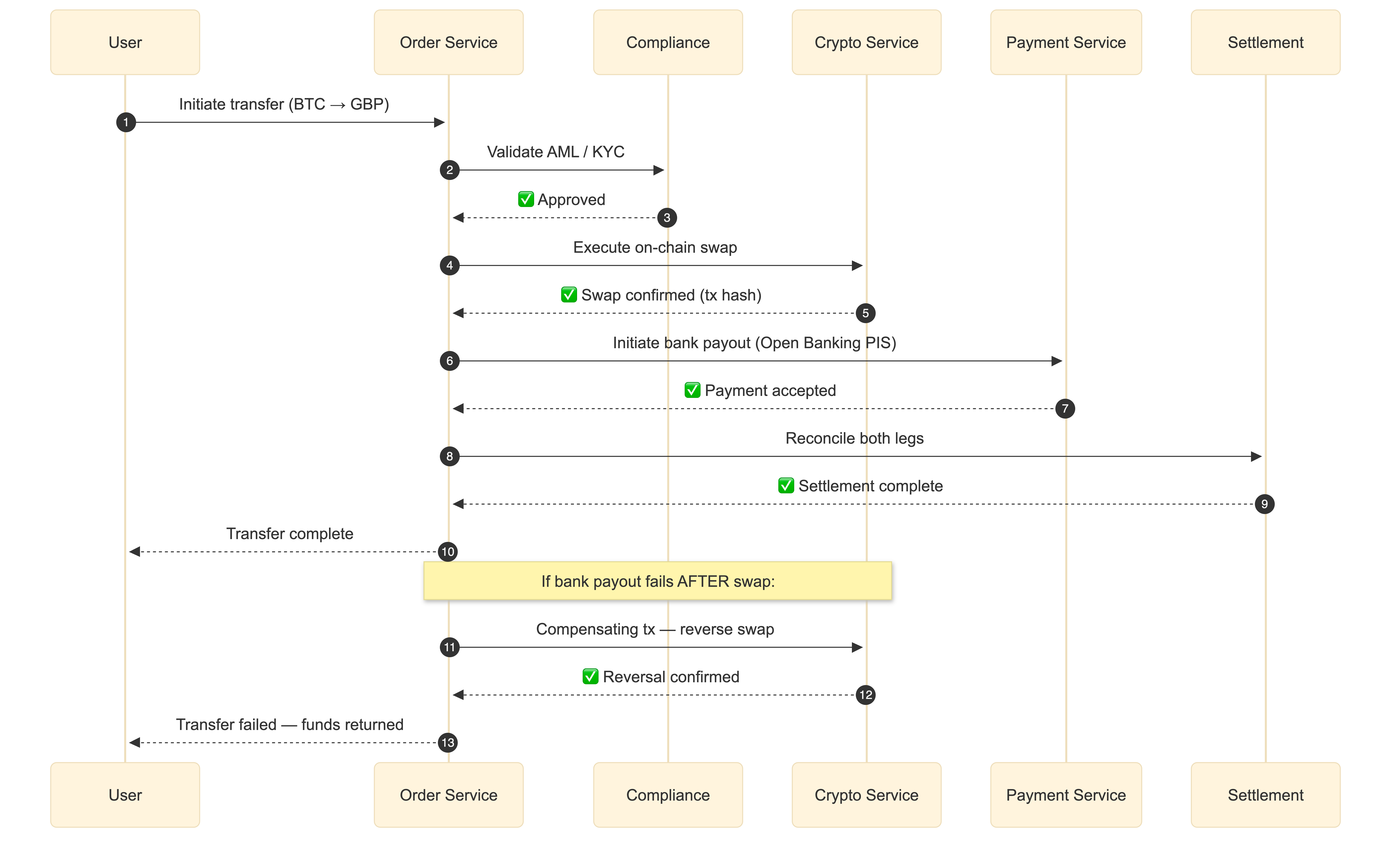
Orchestration via Sagas handles the tightly-coupled flows where you need coordination and compensating transactions. The cross-border crypto-to-fiat transfer I mentioned earlier is a saga: Order Service creates the transfer → Compliance Service validates AML → Crypto Service executes on-chain swap → Payment Service initiates bank transfer → Settlement Service reconciles. If the bank transfer fails after the on-chain swap succeeds, a compensating transaction reverses the swap. You cannot do this with choreography alone unless you enjoy debugging distributed state machines at 3 AM.
The saga in action: crypto-to-fiat transfer
CQRS and event sourcing on the Ledger
For the Ledger and Accounts services, CQRS with event sourcing is non-negotiable. I don't say that lightly - CQRS adds real complexity, and for most services it's overkill. But for financial state management, the properties it gives you are worth the pain.
The write model appends immutable events to a PostgreSQL-backed event store. The read side maintains denormalized projections optimized for specific query patterns - dashboard balances, transaction history, compliance reports. You get a complete audit trail (every state change is an event), the ability to reconstruct any historical account state by replaying events, and temporal queries for free.
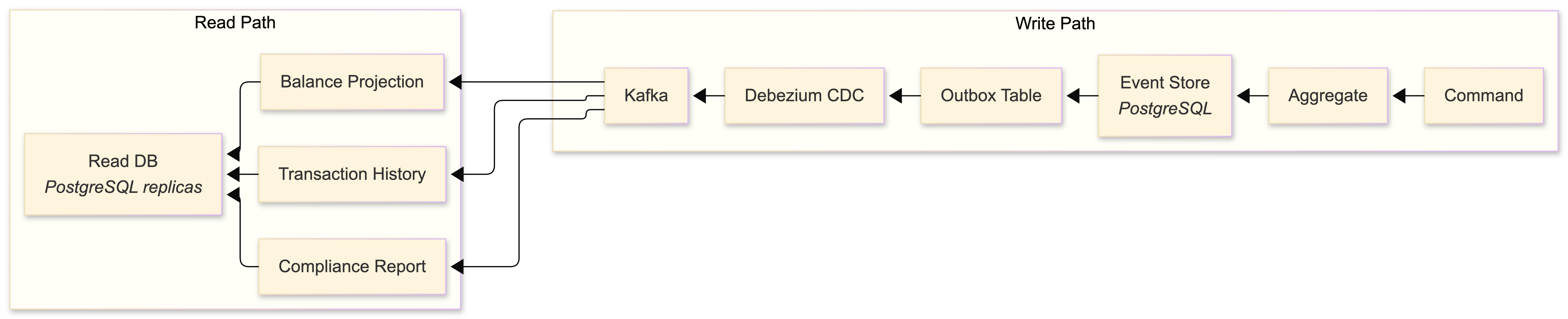
I built the event store directly on PostgreSQL rather than using Kafka as the source of truth for events. Revolut made the same choice. The reasoning: PostgreSQL gives you ACID transactions, rich querying for debugging and compliance, and battle-tested tooling. Kafka is the distribution mechanism, not the system of record. Events are written to PostgreSQL first (in the same transaction as the aggregate update via the Transactional Outbox Pattern), then published to Kafka by a CDC connector or a polling publisher. This eliminates the dual-write problem entirely.
The Transactional Outbox Pattern
This deserves its own callout because getting it wrong is how you lose money. The problem: you need to update your database AND publish a Kafka event atomically. If you do them separately, you get failure modes where the database is updated but the event isn't published (or vice versa). The solution:
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = '...';
INSERT INTO outbox (aggregate_id, event_type, payload)
VALUES ('...', 'payment.debited', '{"amount": 100, ...}');
COMMIT;A separate process (Debezium CDC connector or a custom poller) reads the outbox table and publishes to Kafka. If the publisher crashes, it retries from the last committed offset. The database transaction guarantees atomicity. This is the pattern Square uses in their Books system, and it's the pattern you should use too.
Service-to-service communication
Internal synchronous calls use gRPC with Protocol Buffers. Binary serialization, HTTP/2 multiplexing, strongly-typed contracts with code generation across Go, Rust, and TypeScript - there's no good reason to use JSON REST for internal service communication in 2022. I use buf for managing proto files with linting and breaking change detection.
External and client-facing APIs use REST (documented with OpenAPI 3.0) or GraphQL via Apollo Server for mobile clients that need flexible data fetching. The BFF (Backend-for-Frontend) pattern keeps these separate from internal service contracts.
The service mesh is Istio 1.14 - it automates mTLS between all services, provides circuit breaking and retry policies, and feeds telemetry data to the observability stack. Monzo runs 2,000+ microservices with this pattern. It's not simple to operate, but the alternative (implementing mTLS, circuit breaking, and distributed tracing in every service manually) is worse.
API gateway configuration
Kong sits at the edge. Here's the declarative configuration for the payment service:
_format_version: "3.0"
services:
- name: payment-service
url: http://payment-service.payments:8080
routes:
- name: payment-route
paths: ["/api/v1/payments"]
methods: ["POST", "GET"]
plugins:
- name: rate-limiting
config:
minute: 100
policy: local
- name: key-auth
config:
key_names: ["x-api-key"]
- name: correlation-id
config:
header_name: X-Correlation-ID
generator: uuid
- name: request-transformer
config:
add:
headers: ["X-Request-Start:$(now)"]Every request gets a correlation ID injected at the gateway that follows it through every service, Kafka message, and database write. If you're not doing this, stop reading and go implement it. You cannot debug distributed systems without request-level traceability.
Open Banking integration: the PSD2 reality
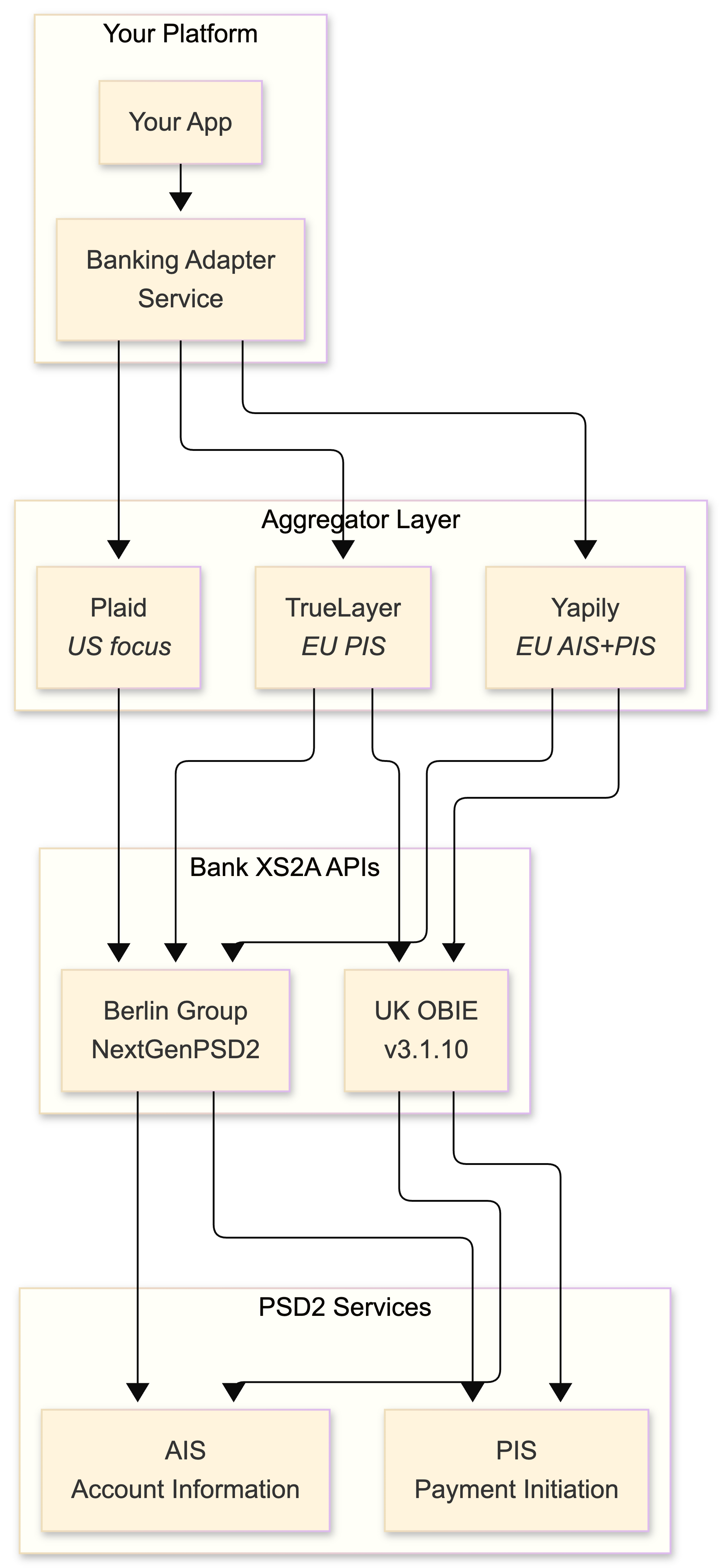
PSD2 mandates that banks expose Access-to-Account (XS2A) APIs to licensed Third-Party Providers. The theory is clean: register as an AISP or PISP with your National Competent Authority, obtain eIDAS certificates (QWAC for TLS, QSEAL for request signing), and connect to banks via standardized APIs.
The practice is a mess. Every bank interprets the Berlin Group NextGenPSD2 or UK OBIE standard differently. Field names change. Error codes are creative. Sandbox environments bear no resemblance to production. Consent flows break in ways that make you question whether the bank's developers have ever tested their own API. Direct bank integration is a path to madness unless you're doing it for exactly one bank and you have a direct relationship with their engineering team.
Aggregators: your shield against bank API chaos
This is where aggregators earn their money. The 2022 landscape:
| Provider | Coverage | Strength | Pricing Model | Notes |
|---|---|---|---|---|
| Plaid | 11,500+ US institutions | US market dominance, Link widget | Per-connection | Weak in Europe |
| TrueLayer | UK + EU PSD2 banks | Payment initiation, PSD2-native | Per-transaction | Strong on PIS flows |
| Yapily | 2,000 banks, 19 EU countries | Pure API infrastructure | Subscription + usage | Doesn't compete at product level |
| Tink | 3,400 banks, 18 EU markets | Breadth, Visa backing | Enterprise | Acquired by Visa, March 2022 |
| Salt Edge | 5,000+ across 47 countries | Global coverage | Per-connection | Best for non-EU markets |
| Nordigen | EU PSD2 banks | Free AIS data | Free (AIS only) | Acquired by GoCardless, July 2022 |
My strategy: Plaid for the US, TrueLayer or Yapily for Europe. Run both behind a Banking Adapter Service that normalizes their data models to your internal canonical schema. This gives you provider redundancy and the ability to switch without touching business logic.
The consent flow
The user-facing flow follows OAuth 2.0 with PSD2-specific extensions:
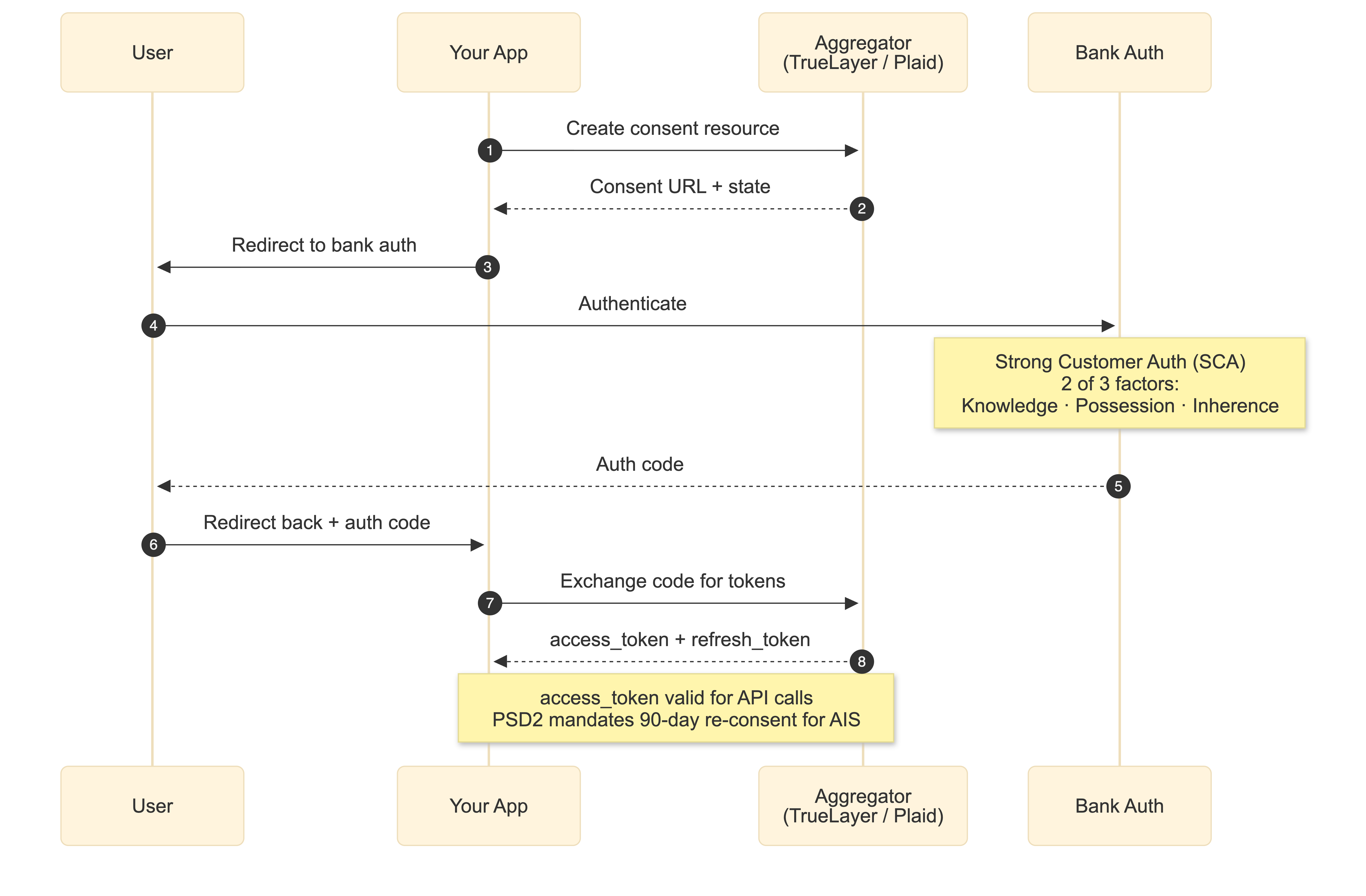
Your backend creates a consent resource, the user is redirected to their bank's auth interface where they perform Strong Customer Authentication (two of three factors: knowledge, possession, inherence - fully enforced across the EEA since March 2022), then redirected back with an authorization code. You exchange that for access and refresh tokens. PSD2 requires 90-day re-consent for AIS access, so plan for consent lifecycle management from day one.
Here's the Plaid integration flow in practice:
// Server-side: Create link_token
const response = await plaidClient.linkTokenCreate({
user: { client_user_id: 'user-id' },
products: ['transactions'],
country_codes: ['US'],
language: 'en'
});
// Client-side: Initialize Plaid Link with link_token
// User authenticates with bank in the Link widget
// onSuccess callback returns public_token
// Server-side: Exchange public_token for persistent access_token
const exchangeResponse = await plaidClient.itemPublicTokenExchange({
public_token: publicToken
});
const accessToken = exchangeResponse.data.access_token;
// Store this encrypted in Vault - this is your persistent bank connectionData normalization: the unsexy critical work
This is the part nobody writes about because it's tedious, but it's where production systems live or die. Plaid returns amounts as positive floats with iso_currency_code. The UK OBIE standard uses ISO 20022-derived JSON with CreditDebitIndicator. Berlin Group uses IBAN-centric schemas with different amount formatting. Your Banking Adapter Service maps all of these to an internal canonical model:
type NormalizedTransaction struct {
ID string `json:"id"`
AccountID string `json:"account_id"`
Amount decimal.Decimal `json:"amount"` // Always signed: negative=debit
Currency string `json:"currency"` // ISO 4217
Direction string `json:"direction"` // DEBIT or CREDIT
Status string `json:"status"` // PENDING, POSTED, CANCELLED
CounterpartyRef string `json:"counterparty_ref"`
BookingDate time.Time `json:"booking_date"`
ValueDate time.Time `json:"value_date"`
ProviderRef string `json:"provider_ref"` // Original ID from provider
Provider string `json:"provider"` // PLAID, TRUELAYER, YAPILY
RawPayload json.RawMessage `json:"raw_payload"` // Original response, for debugging
Metadata map[string]any `json:"metadata"`
}Cache balance data briefly (a few seconds at most), transaction data longer, and invalidate on webhook receipt. Both Plaid (TRANSACTIONS.SYNC_UPDATES_AVAILABLE) and TrueLayer (payment_executed, payment_settled) send webhooks - handle them idempotently with deduplication keys.
Beyond Europe
A quick landscape scan of Open Banking implementations outside PSD2, because if you're building for global coverage you need to know the terrain:
The UK OBIE Read/Write API v3.1.10 is the final version under the CMA roadmap, serving 5 million+ users. It uses FAPI 1.0 Advanced security profiles and is genuinely well-designed. Australia's CDR (Consumer Data Right) uses a similar FAPI profile but adoption has been glacial - 0.31% of eligible consumers. Brazil's Open Finance is the most ambitious implementation globally: 10.5 million active consents, nearly 4 billion API calls by Q3 2022, with mandatory CIBA support for payment scopes and FAPI-based security. The US has no federal mandate - Section 1033 rulemaking at the CFPB is still in progress - so Plaid and FDX fill the gap.
The crypto layer: wallets, chains, and exchange connectivity
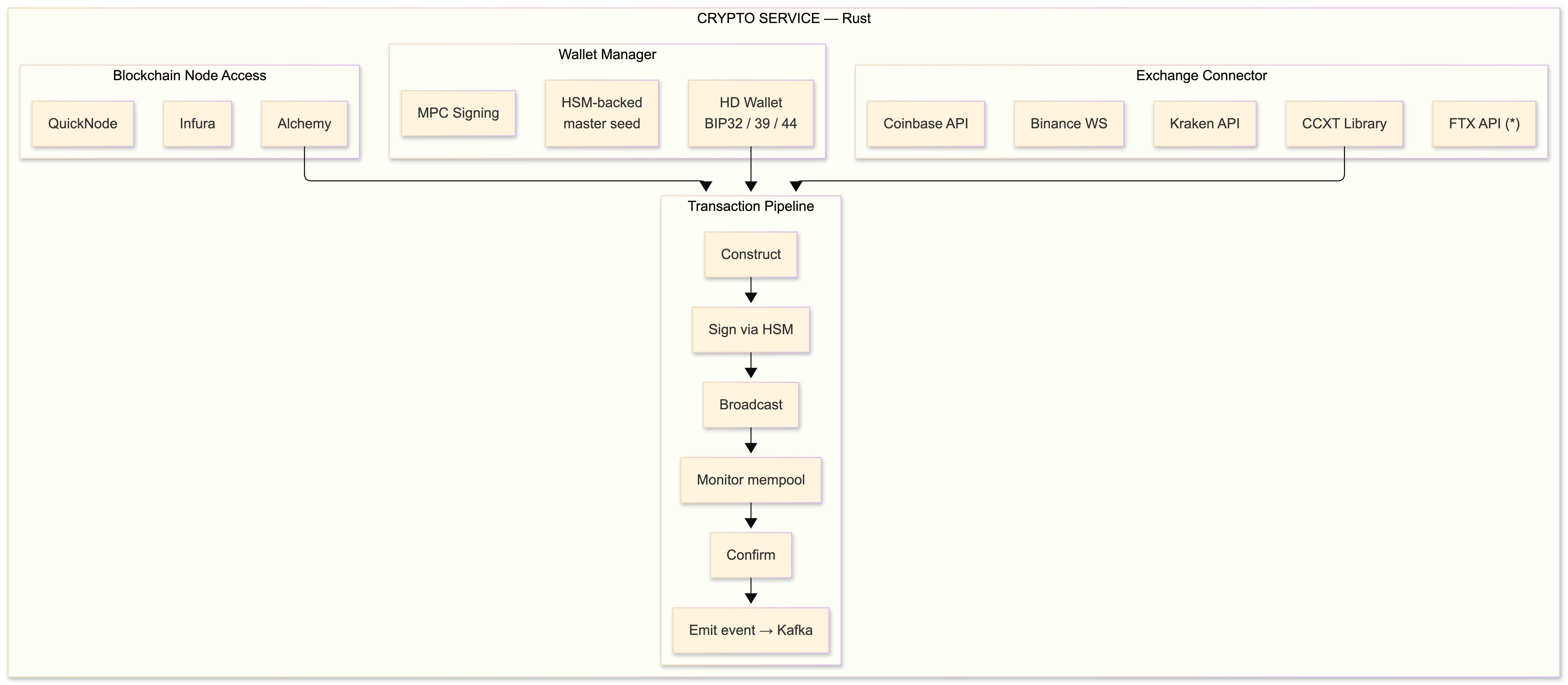
(*) FTX: still operational as of October 2022. Custodial risk discourse incoming.
The crypto layer decomposes into three subsystems: exchange connectivity for trading and liquidity, wallet infrastructure for key management and on-chain operations, and blockchain node access for reading chain state and broadcasting transactions. I write all of this in Rust - the signing paths especially demand memory safety guarantees without GC pauses, and Rust's ownership model delivers exactly that.
Exchange connectivity
The CCXT library is the de facto abstraction layer for exchange APIs. It supports 100+ exchanges with normalized interfaces for order management, market data, and balance queries. The Go bindings are usable but the TypeScript and Python implementations are more mature.
Each exchange has its own authentication and rate limiting:
| Exchange | Auth Method | Rate Limit | WebSocket | Notes |
|---|---|---|---|---|
| Binance | HMAC-SHA256 | 1,200 req weight/min | Yes, streams | Most liquid spot+futures |
| Coinbase | Migrating to JWT/ECDSA | Per-endpoint | Advanced Trade WS | Auth migration in 2022 |
| Kraken | Nonce-based HMAC | 15 calls/sec | V2 WS | Conservative but reliable |
| FTX | HMAC-SHA256 | 30 req/sec | Yes + FIX | FIX protocol support is rare |
FTX deserves a note. As of writing, it's operational and popular for its FIX protocol support and cross-margin system. But if you're building custodial integrations, the counterparty risk is real. I keep exchange balances to the minimum needed for operations and sweep to self-custody on a schedule. This is a principle, not paranoia - any custodial exchange can fail, and your architecture should assume they will.
Wallet architecture: BIP32/39/44
HD (Hierarchical Deterministic) wallets follow the BIP32/BIP39/BIP44 standard. A single master seed derives unlimited key pairs via HMAC-SHA512, organized by coin type:
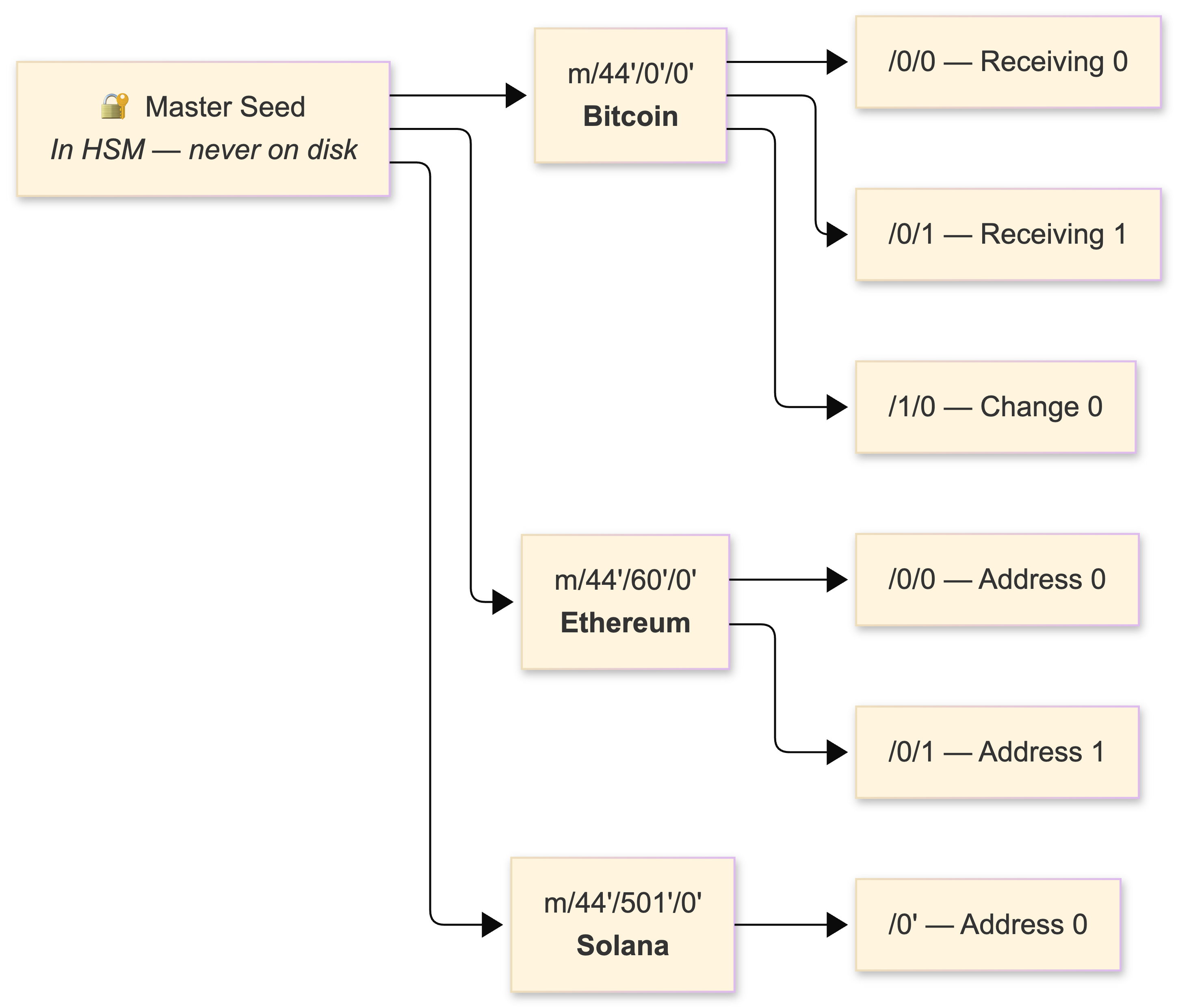
The libraries: ethers.js v5 (v5.6–5.7, the dominant Ethereum library) with its clean Provider/Signer separation, bitcoinjs-lib for UTXO transaction construction, and @solana/web3.js 1.x for Solana. In my Rust services, I use ethers-rs for Ethereum and bitcoin crate for Bitcoin transaction handling.
Custodial models: the post-FTX question
Three options, each with real tradeoffs:
Custodial (you hold keys) - simplest to build, maximum counterparty risk for your users. If you go this route, you are a fiduciary whether your ToS says so or not. Cold storage, multi-sig, air-gapped signing ceremonies, insurance. Most exchanges work this way.
Non-custodial (user holds keys) - eliminates counterparty risk, shifts all complexity to the user. Terrible UX for mainstream users. Private key recovery is a support nightmare.
MPC (Multi-Party Computation) - the emerging middle ground. Key shares are distributed across multiple parties; signing is collaborative without ever reconstructing the full key. Fireblocks and Qredo lead this space. For on-chain multi-sig, Gnosis Safe (2-of-3 or 3-of-5) is the standard on Ethereum. I use MPC for hot wallet operations and HSM-backed cold storage for reserves.
Blockchain node access
I use managed node providers rather than running my own infrastructure. The operational burden of running Ethereum nodes (post-Merge, you need both an execution client and a consensus client) is significant, and Alchemy/Infura have better uptime than I'd achieve:
| Provider | Valuation/Scale | Free Tier | Strength |
|---|---|---|---|
| Alchemy | $10.2B | 300M compute units/mo | Enhanced APIs, webhooks, traces |
| Infura | 400K+ developers | 100K req/day | Mature, MetaMask parent |
| QuickNode | Growing fast | 10M credits/mo | Widest chain support |
The standard Ethereum JSON-RPC calls you'll use constantly: eth_getBalance, eth_estimateGas, eth_sendRawTransaction, eth_feeHistory (for EIP-1559 base fee tracking), and eth_getTransactionReceipt. For Bitcoin: listunspent for UTXO management and estimatesmartfee for fee estimation.
EIP-1559 gas management
Post-London fork, Ethereum uses a dual-fee model: a base fee (algorithmically adjusted per block, targeting 50% utilization, burned) plus a priority fee (tip to validators). The heuristic I use:
maxFeePerGas = 2 × currentBaseFee + maxPriorityFeePerGasThis ensures your transaction remains marketable for roughly six consecutive full blocks. Setting it too low means your transaction sits in the mempool; setting it too high means you overpay (though the excess above baseFee + priorityFee is refunded, so the risk is asymmetric).
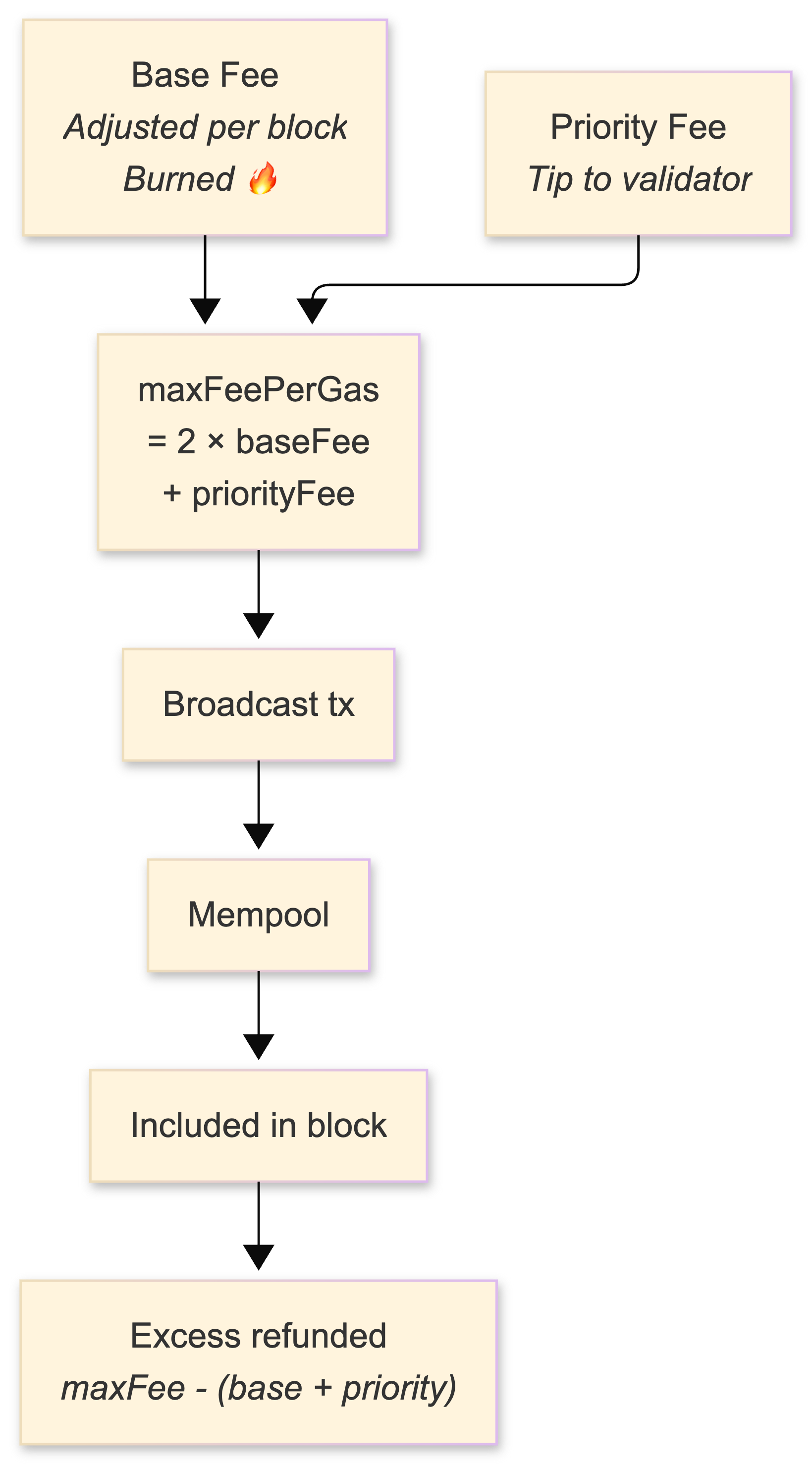
Nonce management is deceptively hard and will bite you in production. Concurrent transactions from the same address require pre-incrementing nonces. A stuck transaction blocks all subsequent transactions from that address. A nonce gap causes indefinite pending state. I maintain a nonce manager service with a Redis-backed atomic counter per address, with stuck-transaction detection and replacement (same nonce, higher gas) on a timer.
Multi-chain support in 2022
The chains that matter right now:
| Chain | Consensus | Block Time | Fees | EVM Compatible | Notes |
|---|---|---|---|---|---|
| Ethereum | PoS (post-Merge, Sep 2022) | ~12s | $1-50+ | Yes (it's the reference) | The Merge didn't reduce fees |
| Bitcoin | PoW | ~10min | $0.50-5 | No | Taproot active since Nov 2021 |
| Polygon | PoS sidechain | ~2s | <$0.01 | Yes | De facto L2 for retail |
| Arbitrum | Optimistic Rollup | ~0.25s | $0.10-1 | Yes | Leading L2 by TVL |
| Optimism | Optimistic Rollup | ~2s | $0.10-1 | Yes | Bedrock upgrade coming |
| Solana | PoH + PoS | ~0.4s | <$0.01 | No | Outage-prone, FTX-adjacent risk |
EVM compatibility is the force multiplier. The same ethers.js code, Solidity contracts, and JSON-RPC interface work across Ethereum, Polygon, Arbitrum, Optimism, and Avalanche - you change chainId and the RPC URL and everything else carries over. This is why I prioritize EVM chains for initial support.
A warning on bridges: cross-chain bridges were catastrophically exploited in 2022. Wormhole ($320M), Ronin ($625M), Nomad ($190M), Harmony Horizon ($100M). That's over a billion dollars lost. If your architecture requires cross-chain value transfer, treat bridge interactions as the highest-risk operations in your system and implement additional verification layers.
Security architecture: defense in depth
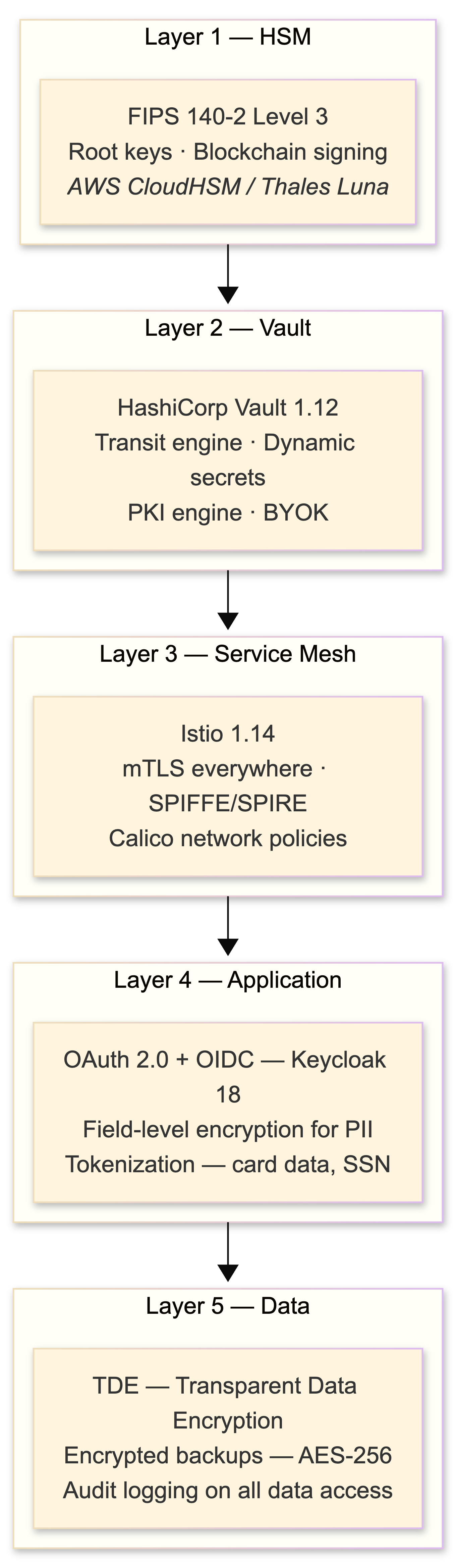
HSM: the root of trust
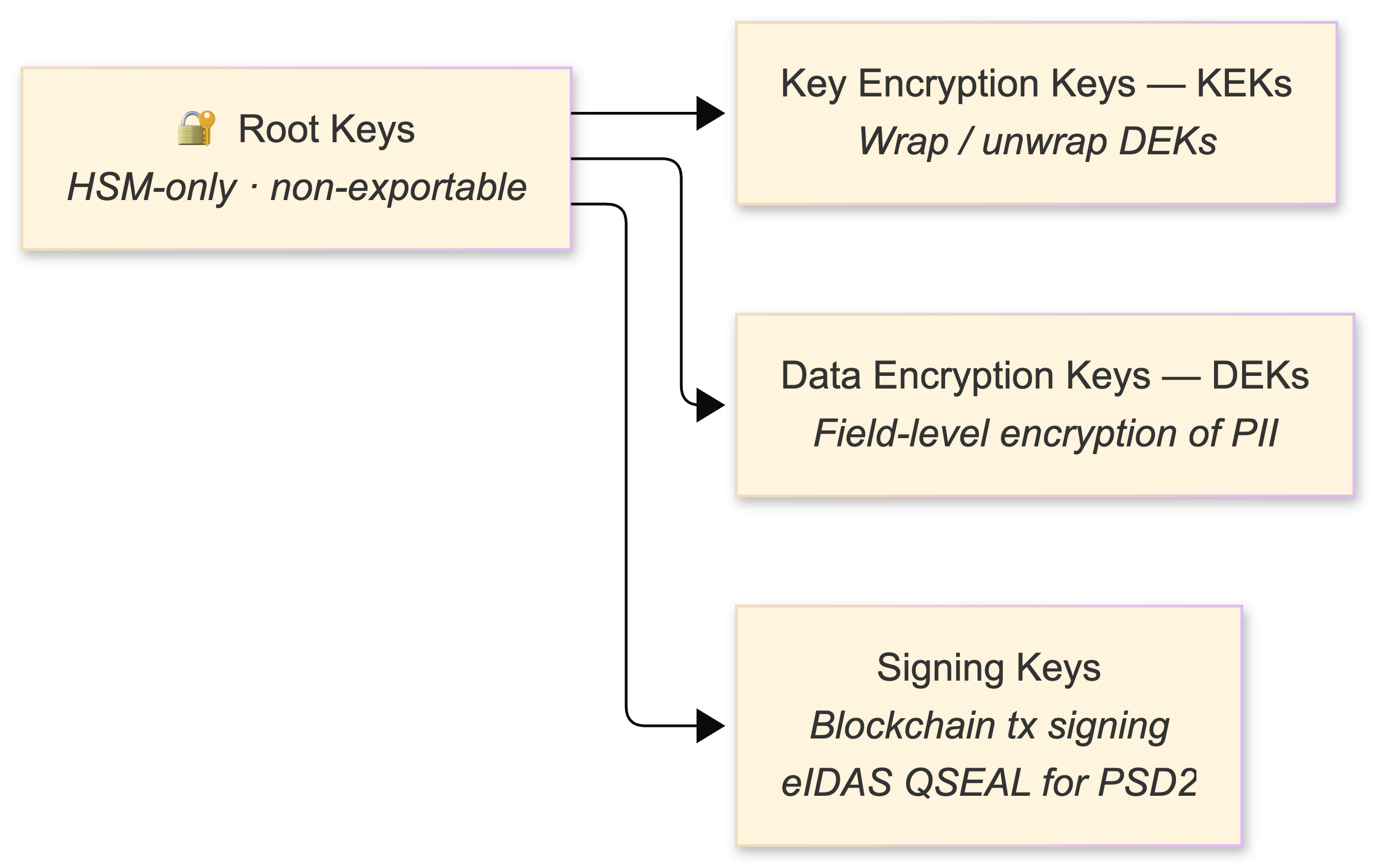
AWS CloudHSM (FIPS 140-2 Level 3, single-tenant, PKCS#11 and JCE APIs) stores root keys and executes blockchain transaction signing. Keys never leave the hardware boundary. The key hierarchy:
HashiCorp Vault
I run Vault 1.12, which shipped with PKCS#11 provider support - Vault can now act as an HSM interface for software that expects PKCS#11. The Transit secrets engine is the workhorse:
# Encrypt sensitive data
vault write transit/encrypt/payment-data \
plaintext=$(echo -n "sensitive-pii" | base64)
# Response: ciphertext = vault:v1:AbC123...
# The v1 is the key version - enables rotation
# Rotate the encryption key
vault write -f transit/keys/payment-data/rotate
# Re-encrypt existing ciphertext with new key version
vault write transit/rewrap/payment-data \
ciphertext="vault:v1:AbC123..."
# Response: ciphertext = vault:v2:XyZ789...
# No plaintext exposed during rotationThe rewrap endpoint is critical - it re-encrypts existing ciphertext with the latest key version without ever exposing plaintext. This means you can rotate keys on a schedule (I do monthly) without a mass re-encryption job touching your database.
Vault 1.11 introduced BYOK (Bring Your Own Key) for importing HSM-generated keys into Transit, which lets me use HSM for key generation and Vault for operational key management - best of both worlds.
Authentication: OAuth 2.0 + OIDC
I run Keycloak 18 (self-hosted) for identity management. User-facing flows use Authorization Code with PKCE. Service-to-service uses Client Credentials. JWTs are short-lived (10 minutes) with refresh tokens, signed via ES256 (ECDSA on P-256 - faster verification than RS256 and smaller tokens). JWKS endpoints rotate signing keys.
For PSD2 SCA, dynamic linking binds the authentication cryptographically to the specific transaction amount and payee. This isn't optional - if you're initiating payments as a PISP, you must implement this.
mTLS everywhere
Istio automates mTLS between all services with SPIFFE workload identities. External TLS uses cert-manager v1.9 on Kubernetes for automated Let's Encrypt certificate issuance. TLS 1.3 everywhere, TLS 1.2 as the absolute minimum per PCI DSS. Internal certificates are short-lived (24-hour rotation) because compromise windows should be measured in hours, not months.
Tech stack: choosing languages by domain
I don't believe in one-language shops for a system this diverse. Each language earns its place:

Go 1.19 (generics landed in 1.18, still stabilizing) is the backbone. Goroutines give you lightweight concurrency for high-volume transaction processing without the thread-pool complexity of Java. Compiled binaries produce tiny Docker images (usually under 20MB with FROM scratch). Monzo and Coinbase both run Go extensively. I use Gin for REST APIs and go-kit where I need explicit middleware chains.
Rust handles the crypto-critical paths. Signing operations, key derivation, exchange WebSocket feed processing, and anything where you need predictable latency without GC pauses. Axum (Tokio-based) is my web framework choice - it's ergonomic, composes well with Tower middleware, and the async runtime performance is excellent. Rust is 2-3x faster than Go in compute-bound benchmarks, and the ownership model catches entire categories of bugs at compile time.
Node.js/TypeScript with NestJS 9 powers the BFF layer. NestJS provides built-in support for Kafka, Redis, NATS, and gRPC transports - ideal for aggregating data from multiple backend services into client-friendly GraphQL responses.
Python with FastAPI handles ML model serving, risk scoring, and the KYC/AML pipeline. Django serves the back-office admin. Python has no business being on the hot path of financial transactions, but for ML inference and admin interfaces it's the pragmatic choice.
Messaging and schema management
Kafka topics follow domain-driven naming: {domain}.{entity}.{event}.{version}. Examples:
payments.transaction.created.v1
payments.transaction.completed.v1
payments.transaction.failed.v1
accounts.balance.updated.v1
compliance.kyc.verified.v1
compliance.aml.flagged.v1
crypto.wallet.transfer.signed.v1
crypto.wallet.transfer.confirmed.v1
banking.consent.granted.v1
banking.consent.expired.v1Partition by account_id to guarantee per-account ordering. Replication factor 3 with min.insync.replicas=2. Schemas are Avro or Protobuf, managed by Confluent Schema Registry with backward compatibility enforced. Exactly-once semantics (idempotent producers, enabled by default in Kafka 3.0+) are essential - though external side effects (blockchain transactions, bank API calls) still require application-level idempotency. Kafka gives you exactly-once within its boundary; you're responsible for the rest.
The data layer: ledgers, event stores, and time-series
Double-entry bookkeeping ledger
This is the gravitational center of the system. Every financial operation - fiat deposit, crypto purchase, fee deduction, internal transfer - is recorded as a balanced journal entry. I built this following Square's "Books" architecture: immutable, append-only, with corrections recorded as reversing entries rather than mutations.
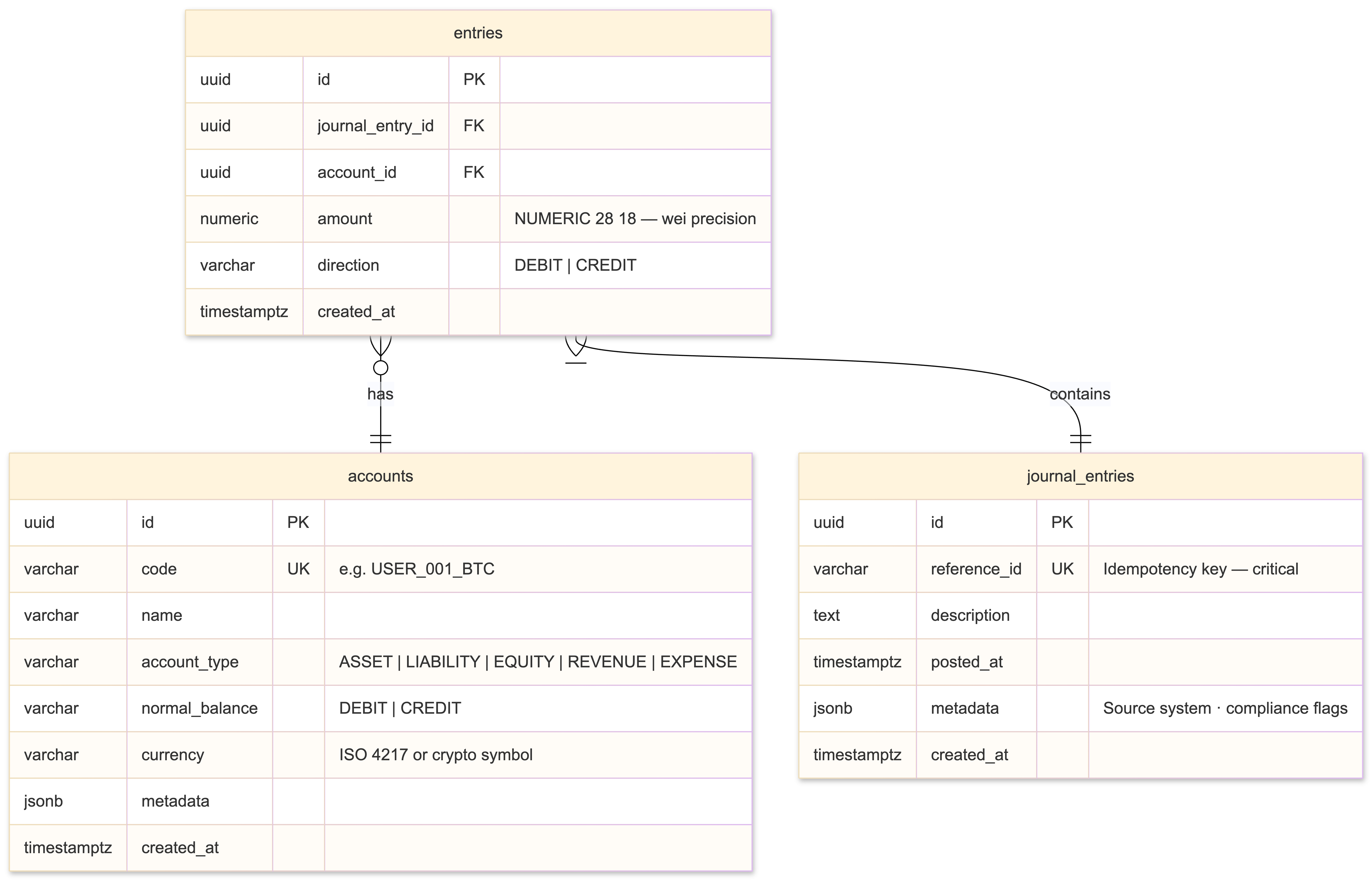
-- The three core tables. That's it. Simplicity is load-bearing here.
CREATE TABLE accounts (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
code VARCHAR(20) UNIQUE NOT NULL, -- e.g., 'USER_001_BTC', 'FEE_REVENUE_USD'
name VARCHAR(255) NOT NULL,
account_type VARCHAR(50) NOT NULL, -- ASSET, LIABILITY, EQUITY, REVENUE, EXPENSE
normal_balance VARCHAR(10) NOT NULL, -- DEBIT or CREDIT
currency VARCHAR(10) DEFAULT 'USD', -- ISO 4217 or crypto symbol
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT now()
);
CREATE TABLE journal_entries (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
reference_id VARCHAR(255) UNIQUE, -- Idempotency key. Critical.
description TEXT,
posted_at TIMESTAMPTZ DEFAULT now(),
metadata JSONB, -- Source system, compliance flags, etc.
created_at TIMESTAMPTZ DEFAULT now()
);
CREATE TABLE entries (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
journal_entry_id UUID NOT NULL REFERENCES journal_entries(id),
account_id UUID NOT NULL REFERENCES accounts(id),
amount NUMERIC(28,18) NOT NULL, -- 18 decimals for wei-precision crypto
direction VARCHAR(10) NOT NULL CHECK (direction IN ('DEBIT', 'CREDIT')),
created_at TIMESTAMPTZ DEFAULT now()
);
-- Enforce the iron law: every journal entry must balance
CREATE OR REPLACE FUNCTION check_journal_balance()
RETURNS TRIGGER AS $$
BEGIN
IF (
SELECT SUM(CASE WHEN direction = 'DEBIT' THEN amount ELSE -amount END)
FROM entries
WHERE journal_entry_id = NEW.journal_entry_id
) != 0 THEN
RAISE EXCEPTION 'Journal entry does not balance';
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- Idempotent insert pattern
INSERT INTO journal_entries (id, reference_id, description, metadata)
VALUES ($1, $2, $3, $4)
ON CONFLICT (reference_id) DO NOTHING
RETURNING id;The reference_id UNIQUE constraint is your idempotency guarantee. If a Kafka consumer retries processing an event, the duplicate insert is silently ignored. NUMERIC(28,18) handles both fiat precision (2-4 decimal places) and crypto precision (Ethereum wei has 18 decimal places). Using NUMERIC instead of BIGINT with implicit scaling avoids an entire category of conversion bugs.
Event store
CREATE TABLE event_store (
event_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
aggregate_id UUID NOT NULL,
aggregate_type VARCHAR(100) NOT NULL, -- 'Account', 'Payment', 'Transfer'
event_type VARCHAR(100) NOT NULL, -- 'BalanceDebited', 'PaymentInitiated'
event_data JSONB NOT NULL,
metadata JSONB, -- correlation_id, causation_id, user_id
version INTEGER NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
UNIQUE(aggregate_id, version) -- Optimistic concurrency control
);
CREATE INDEX idx_event_store_aggregate
ON event_store (aggregate_id, version ASC);
CREATE INDEX idx_event_store_type_time
ON event_store (event_type, created_at);The UNIQUE(aggregate_id, version) constraint provides optimistic concurrency control. If two concurrent processes try to append version N+1 for the same aggregate, one succeeds and the other gets a constraint violation. Retry with fresh state - no distributed locks needed.
Range-partition the entries table by month:
CREATE TABLE entries (
-- ... columns as above ...
) PARTITION BY RANGE (created_at);
CREATE TABLE entries_2022_10 PARTITION OF entries
FOR VALUES FROM ('2022-10-01') TO ('2022-11-01');
CREATE TABLE entries_2022_11 PARTITION OF entries
FOR VALUES FROM ('2022-11-01') TO ('2022-12-01');This gives you partition-level maintenance (VACUUM, REINDEX on specific months), eliminates insert contention across periods, and enables cost-effective archival of old partitions.
Rate limiting with Redis
Sliding window rate limiting using sorted sets - atomic via Lua script:
-- rate_limit.lua
local key = KEYS[1]
local window = tonumber(ARGV[1])
local limit = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local unique_id = ARGV[4]
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)
local count = redis.call('ZCARD', key)
if count < limit then
redis.call('ZADD', key, now, unique_id)
redis.call('EXPIRE', key, window)
return 1 -- allowed
else
return 0 -- rate limited
endI use this for API rate limiting, exchange API call budgeting, and per-account transaction velocity checks (part of the AML pipeline).
Market data time-series
TimescaleDB hypertables with continuous aggregates for OHLCV computation:
CREATE TABLE tick_data (
time TIMESTAMPTZ NOT NULL,
symbol VARCHAR(20) NOT NULL,
exchange VARCHAR(20) NOT NULL,
price NUMERIC(28,18) NOT NULL,
volume NUMERIC(28,18) NOT NULL
);
SELECT create_hypertable('tick_data', 'time');
-- Continuous aggregate: 1-minute OHLCV bars, computed automatically
CREATE MATERIALIZED VIEW ohlcv_1m
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 minute', time) AS bucket,
symbol,
exchange,
FIRST(price, time) AS open,
MAX(price) AS high,
MIN(price) AS low,
LAST(price, time) AS close,
SUM(volume) AS volume
FROM tick_data
GROUP BY time_bucket('1 minute', time), symbol, exchange;
-- Refresh policy: materialize every minute, up to 10 minutes ago
SELECT add_continuous_aggregate_policy('ohlcv_1m',
start_offset => INTERVAL '1 hour',
end_offset => INTERVAL '10 minutes',
schedule_interval => INTERVAL '1 minute'
);QuestDB is the alternative if raw query speed is your bottleneck - it benchmarks at 25ms for OHLCV queries versus TimescaleDB's ~1s, thanks to column-oriented storage and ASOF JOIN support. I use TimescaleDB because it's PostgreSQL-native (one fewer operational dependency) and the continuous aggregate feature eliminates the need for a separate aggregation pipeline.
Observability: you cannot debug what you cannot see
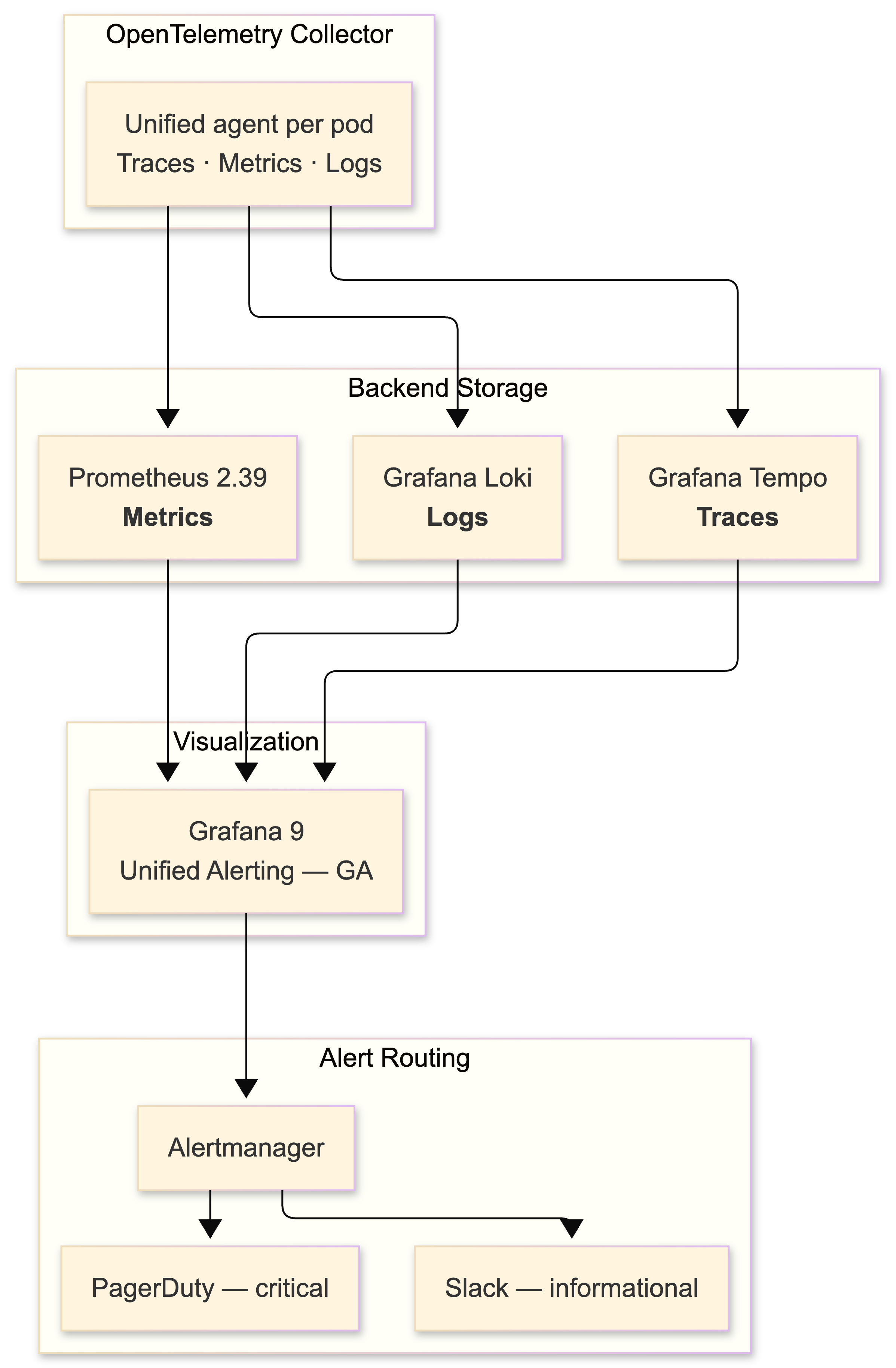
The 2022 stack: Prometheus 2.39 for metrics, Grafana 9 for visualization (unified alerting became GA this year), Grafana Tempo for distributed tracing, and Grafana Loki for log aggregation.
I chose the LGTM stack (Loki, Grafana, Tempo, Mimir) over ELK because Loki's label-based indexing model is dramatically cheaper at scale - it doesn't index log content, only metadata labels. For financial services where log volumes are extreme (every API call, every database query, every Kafka message), the cost difference is significant.
OpenTelemetry is the unification layer. Tracing is GA, metrics are stabilizing, logs are still maturing. The OTel Collector acts as the single collection agent in each pod, routing traces to Tempo, metrics to Prometheus, and logs to Loki.
Structured logging: every log line is queryable
Every log entry is structured JSON with a correlation ID:
{
"timestamp": "2022-10-15T14:30:00.000Z",
"level": "INFO",
"service": "payment-service",
"trace_id": "abc123def456",
"span_id": "789ghi",
"correlation_id": "txn-pay-20221015-001",
"message": "Payment initiated via Open Banking",
"payment_id": "pay_abc123",
"amount_minor": 10000,
"currency": "GBP",
"provider": "TRUELAYER",
"bank_id": "ob-monzo",
"duration_ms": 245,
"user_id": "usr_xyz"
}The correlation_id follows a transaction from API gateway through every microservice, Kafka message, and database write. When something goes wrong at 2 AM, you grep for the correlation ID and get the complete distributed trace of what happened.
SLOs and error budgets
Define SLOs rigorously and alert on error budget burn rate, not raw thresholds:
| SLO | Target | 30-day budget |
|---|---|---|
| Payment API availability | 99.9% | 43.2 minutes downtime |
| P99 latency (payment endpoint) | < 500ms | 0.1% of requests can exceed |
| Transaction success rate | 99.95% | 0.05% failure budget |
| Ledger consistency | 100% | Zero tolerance |
Fast-burn alerts (5-minute window) catch incidents. Slow-burn alerts (1-hour window) catch degradation. This produces far fewer false positives than naive threshold alerts. I route through Alertmanager to PagerDuty for critical paths and Slack for informational.
Hosting and deployment: Kubernetes, Terraform, GitOps
Infrastructure provisioning
Managed Kubernetes on AWS EKS with Graviton3 instances for cost efficiency (Coinbase migrated 3,500 services to Graviton and reported 15%+ savings). Companion services: RDS for PostgreSQL, ElastiCache for Redis, MSK for Kafka, CloudHSM for key management.
Terraform 1.3 provisions everything, with modules separated by concern:
infrastructure/
├── terraform/
│ ├── modules/
│ │ ├── networking/ # VPC, subnets, NAT, security groups
│ │ ├── eks/ # EKS cluster, node groups, IRSA
│ │ ├── data/ # RDS, ElastiCache, MSK
│ │ ├── security/ # CloudHSM, KMS, IAM roles
│ │ └── observability/ # Prometheus, Grafana, log buckets
│ ├── environments/
│ │ ├── staging/
│ │ │ └── main.tf # Module composition for staging
│ │ └── production/
│ │ └── main.tf # Module composition for prod
│ └── backend.tf# backend.tf - state management
terraform {
required_version = ">= 1.3"
backend "s3" {
bucket = "fintech-terraform-state"
key = "production/eks/terraform.tfstate"
region = "eu-west-1"
dynamodb_table = "terraform-locks"
encrypt = true
}
}
# EKS cluster with Graviton node groups
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 18.0"
cluster_name = "fintech-prod"
cluster_version = "1.24"
vpc_id = module.networking.vpc_id
subnet_ids = module.networking.private_subnet_ids
eks_managed_node_groups = {
core = {
instance_types = ["m6g.xlarge"] # Graviton
min_size = 3
max_size = 10
desired_size = 5
labels = { workload = "core" }
}
compute = {
instance_types = ["c6g.2xlarge"] # Graviton, compute-optimized
min_size = 2
max_size = 20
desired_size = 4
labels = { workload = "compute" }
capacity_type = "SPOT" # Spot for non-critical
}
}
}GitOps with ArgoCD
Terraform handles Day 0/1 (infrastructure provisioning). ArgoCD 2.5 handles Day 2 (application deployment). The App-of-Apps pattern lets a root ArgoCD application manage all others declaratively from a Git repo:
# argocd/apps/payment-service.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: payment-service
namespace: argocd
spec:
project: fintech
source:
repoURL: https://github.com/myorg/fintech-manifests.git
targetRevision: main
path: services/payment-service
destination:
server: https://kubernetes.default.svc
namespace: payments
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueThe deployment pipeline: end to end

Canary releases with Flagger
I use Flagger with Istio VirtualServices for progressive traffic shifting. New deployments start at 5% traffic, automatically promoted to 10% → 20% → 50% → 100% if metrics stay healthy, with automatic rollback if request success rate drops below 99% or P99 latency exceeds 500ms:
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: payment-service
namespace: payments
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: payment-service
service:
port: 8080
analysis:
interval: 30s
threshold: 5 # Max failed checks before rollback
maxWeight: 50 # Max traffic percentage to canary
stepWeight: 10 # Increment per interval
metrics:
- name: request-success-rate
thresholdRange:
min: 99
interval: 1m
- name: request-duration
thresholdRange:
max: 500 # P99 < 500ms
interval: 1mCI/CD pipeline
GitHub Actions with OIDC for AWS authentication (no stored credentials - an addition that should be mandatory):
# .github/workflows/deploy.yml
name: Deploy
on:
push:
branches: [main]
permissions:
id-token: write
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Configure AWS credentials (OIDC)
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-arn: arn:aws:iam::123456789:role/github-actions
aws-region: eu-west-1
- name: Build and push to ECR
run: |
aws ecr get-login-password | docker login --username AWS --password-stdin $ECR_REGISTRY
docker build -t $ECR_REGISTRY/payment-service:${{ github.sha }} .
docker push $ECR_REGISTRY/payment-service:${{ github.sha }}
- name: Update manifest
run: |
cd manifests/services/payment-service
kustomize edit set image payment-service=$ECR_REGISTRY/payment-service:${{ github.sha }}
git commit -am "deploy: payment-service ${{ github.sha }}"
git push
# ArgoCD detects the manifest change and deploys via Flagger canaryCost optimization
Use Spot instances for non-critical workloads (market data ingestion, analytics, batch jobs). Reserved Instances for baseline capacity (core ledger, API gateways, databases). Horizontal Pod Autoscaler with custom Prometheus metrics for elastic scaling based on actual business metrics (transactions per second, not just CPU). Storage tiering moves cold time-series data to S3 via Kafka S3 Sink Connector - hot data stays in TimescaleDB, warm moves to S3 Parquet for Athena queries.
Regulatory landscape: navigating PSD2, MiCA, and the compliance gauntlet
If you're operating at the intersection of crypto and banking in 2022, you're subject to a regulatory matrix that would make a compliance lawyer weep.
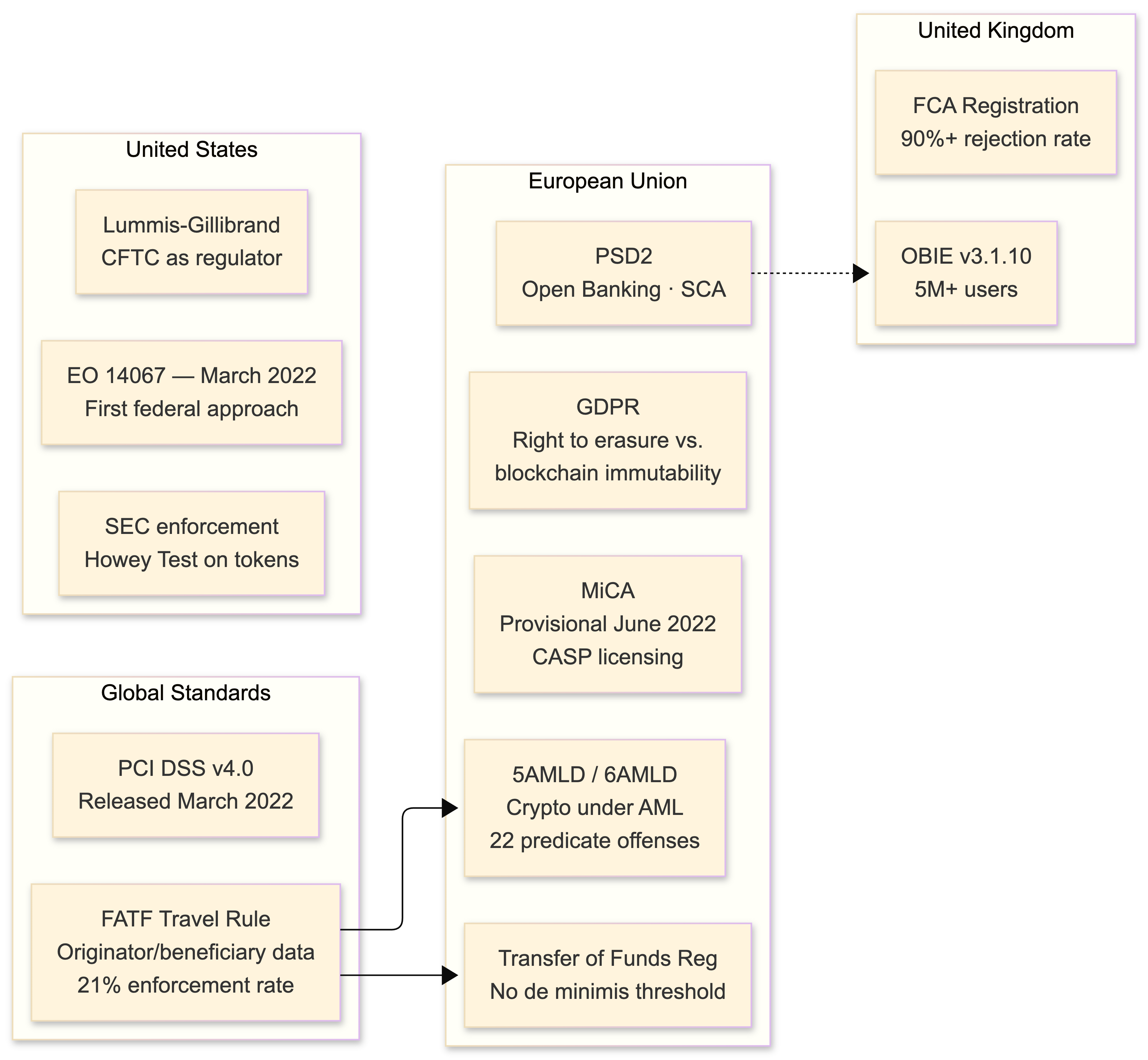
PSD2 (Payment Services Directive 2)
Governs Open Banking access. SCA enforcement is live and mandatory. 90-day consent renewal for AIS. The technical standards (RTS on SCA) specify exactly how Strong Customer Authentication must work, including the dynamic linking requirement for payment initiation. If you're a PISP, every payment must be cryptographically bound to the specific amount and payee during the SCA flow.
MiCA (Markets in Crypto-Assets Regulation)
Reached provisional political agreement on June 30, 2022. This is the big one for Europe. It creates licensing requirements for CASPs (Crypto-Asset Service Providers), stablecoin reserve requirements (reserve assets must be liquid and cover 100% of outstanding tokens), consumer protection mandates, and - critically - an EU passport that allows cross-border operation with a single license. Formal adoption is expected in 2023, with an 18-month implementation period. If you're building for EU markets, start your CASP licensing process now.
AML/CFT: 5AMLD, 6AMLD, and the FATF Travel Rule
The 5th and 6th Anti-Money Laundering Directives brought crypto exchanges under AML obligations. 6AMLD harmonized 22 predicate offenses and raised minimum imprisonment to 4 years. The FATF Travel Rule requires that crypto transfers between VASPs include originator and beneficiary information. Implementation has been poor globally - only 21% of jurisdictions have taken enforcement action - but that's changing fast. Notabene and Chainalysis provide Travel Rule compliance tooling via TRISA and OpenVASP protocols.
The EU's Transfer of Funds Regulation applies with no de minimis threshold for CASP-to-CASP transfers. Yes, that means even a $5 transfer requires full originator/beneficiary data exchange.
GDPR vs. blockchain immutability
GDPR's right to erasure creates tension with blockchain's immutability. The pragmatic architecture: store all personal data off-chain (your PostgreSQL database), put only cryptographic hashes on-chain for verification. For any encrypted data that did end up on-chain, encryption key disposal renders it functionally erased - this is the most widely adopted compliance approach and the one most DPAs have signaled acceptance of.
KYC/AML implementation
Dual-rail: identity verification (Jumio, Onfido, Sumsub for document + biometric verification) plus blockchain analytics (Chainalysis KYT for real-time transaction monitoring across 100+ blockchains). The OFAC designation of Tornado Cash wallet addresses in August 2022 made crypto-specific sanctions screening mandatory - your Chainalysis or Elliptic integration needs to flag any interaction with sanctioned addresses before transactions are broadcast.
The US: regulation by enforcement
Executive Order 14067 (March 2022) was the first comprehensive federal approach to crypto, directing agencies to study CBDCs and coordinate on regulation. The SEC continues regulation-by-enforcement, applying the Howey Test to tokens. The Lummis-Gillibrand bill proposes the CFTC as primary spot market regulator but hasn't passed. The UK FCA's registration regime rejected over 90% of crypto firm applicants. Plan for regulatory divergence across jurisdictions - your compliance engine needs configurable rulesets per market.
Conclusion: convergence as an architectural discipline
The convergence of crypto and traditional banking is not a product decision - it's an architectural one. The systems that survive will share several properties: event-sourced ledgers that provide immutable audit trails satisfying both banking regulators and blockchain transparency expectations; CQRS that separates the write-hot path of transaction processing from the read-heavy compliance reporting and dashboards; MPC or HSM-backed key management that eliminates single points of custodial failure; and multi-provider abstraction layers that insulate business logic from the inevitable churn of aggregator acquisitions and exchange collapses.
The Ethereum Merge proved that foundational protocol changes can ship without disrupting the developer API surface. PSD2 enforcement proved that regulatory mandates drive adoption at scale - a billion monthly transactions don't lie. And MiCA's arrival signals that the regulatory arbitrage window is closing for crypto operators in Europe.
Build for immutability. Design for auditability. Assume that any external dependency - exchange, bank API, aggregator, bridge - will fail or change without warning. The architecture I've outlined here provides the resilience to absorb those shocks while maintaining the consistency that financial operations demand.
If you got this far, you either care about this problem deeply or you're procrastinating on something else. Either way, I hope this was useful. The code examples are production-informed, the architecture is battle-tested, and the regulatory overview is current as of October 2022. Things will change - they always do in this space - but the foundational patterns won't.
If you're facing similar challenges, let's talk.
Bring the current architecture context and delivery constraints, and we can map out a focused next step.
Book a Discovery CallNewsletter
Stay connected
Not ready for a call? Get the next post directly.